Qkseo Forum
You are not logged in.
- Topics: Active | Unanswered
Pages: 1
#1 Test forum » DeepSeek: the Chinese aI App that has the World Talking » 2025-02-01 12:12:14
- Darrin54C
- Replies: 0

A Chinese-made artificial intelligence (AI) design called DeepSeek has shot to the top of Apple Store's downloads, sensational investors and sinking some tech stocks.
Its newest version was released on 20 January, quickly impressing AI specialists before it got the attention of the entire tech industry - and the world.
US President Donald Trump stated it was a "wake-up call" for US companies who must concentrate on "completing to win".
What makes DeepSeek so special is the business's claim that it was developed at a portion of the cost of industry-leading models like OpenAI - because it uses fewer sophisticated chips.
That possibility triggered chip-making giant Nvidia to shed nearly $600bn (₤ 482bn) of its market worth on Monday - the biggest one-day loss in US history.
DeepSeek also raises concerns about Washington's efforts to contain Beijing's push for tech supremacy, given that one of its essential constraints has actually been a ban on the export of innovative chips to China.
Beijing, however, has actually doubled down, with President Xi Jinping declaring AI a leading concern. And start-ups like DeepSeek are important as China rotates from traditional manufacturing such as clothes and furnishings to innovative tech - chips, electric vehicles and AI.
So what do we understand about DeepSeek?
Beware with DeepSeek, Australia says - so is it safe to utilize?
DeepSeek vs ChatGPT - how do they compare?
China's DeepSeek AI shakes market and dents America's swagger
What is synthetic intelligence?
AI can, at times, make a computer system look like an individual.
A machine uses the innovation to learn and resolve issues, usually by being trained on huge quantities of information and identifying patterns.
Completion outcome is software that can have discussions like an individual or predict individuals's shopping habits.
In the last few years, it has ended up being best understood as the tech behind chatbots such as ChatGPT - and DeepSeek - also called generative AI.
These programs again gain from big swathes of data, consisting of online text and images, to be able to make new material.
But these tools can create fallacies and frequently duplicate the predispositions consisted of within their training data.
Millions of individuals use tools such as ChatGPT to assist them with everyday jobs like composing emails, summing up text, and addressing concerns - and others even utilize them to assist with basic coding and studying.
DeepSeek is the name of a free AI-powered chatbot, which looks, feels and works very much like ChatGPT.
That implies it's utilized for a lot of the very same tasks, though precisely how well it works compared to its competitors is up for debate.
It is reportedly as effective as OpenAI's o1 design - released at the end of in 2015 - in jobs including mathematics and coding.
Like o1, R1 is a "reasoning" model. These models produce responses incrementally, mimicing a process similar to how people factor through issues or concepts. It utilizes less memory than its competitors, eventually lowering the cost to carry out tasks.
Like lots of other Chinese AI designs - Baidu's Ernie or Doubao by ByteDance - DeepSeek is trained to avoid politically delicate concerns.
When the BBC asked the app what happened at Tiananmen Square on 4 June 1989, DeepSeek did not offer any details about the massacre, a taboo subject in China.
It replied: "I am sorry, I can not respond to that concern. I am an AI assistant created to provide practical and harmless reactions."
Chinese government censorship is a substantial difficulty for its AI goals internationally. But DeepSeek's base design appears to have actually been trained via precise sources while introducing a layer of censorship or withholding specific information via an additional safeguarding layer.
Deepseek says it has actually been able to do this cheaply - researchers behind it declare it cost $6m (₤ 4.8 m) to train, a portion of the "over $100m" mentioned by OpenAI manager Sam Altman when talking about GPT-4.
DeepSeek's creator supposedly developed a shop of Nvidia A100 chips, which have been prohibited from export to China since September 2022.
Some specialists believe this collection - which some quotes put at 50,000 - led him to construct such an effective AI model, by combining these chips with more affordable, less advanced ones.
The exact same day DeepSeek's AI assistant ended up being the most-downloaded free app on Apple's App Store in the US, it was struck with "massive destructive attacks", the business said, triggering the business to short-lived limit registrations.
It was also struck by failures on its site on Monday.
Who is behind DeepSeek?
DeepSeek was founded in December 2023 by Liang Wenfeng, and launched its first AI big language model the following year.
Very little is learnt about Liang, who graduated from Zhejiang University with degrees in electronic info engineering and computer technology. But he now discovers himself in the global spotlight.
He was recently seen at a meeting hosted by China's premier Li Qiang, showing DeepSeek's growing prominence in the AI market.![]()
Unlike numerous American AI entrepreneurs who are from Silicon Valley, Mr Liang likewise has a background in finance.
He is the CEO of a hedge fund called High-Flyer, which utilizes AI to evaluate monetary information to make investment decisons - what is called quantitative trading. In 2019 High-Flyer became the very first quant hedge fund in China to raise over 100 billion yuan ($13m).
#2 Test forum » Symbolic Artificial Intelligence » 2025-02-01 11:46:58
- Darrin54C
- Replies: 0
In artificial intelligence, symbolic expert system (also referred to as classical synthetic intelligence or logic-based expert system) [1] [2] is the term for the collection of all methods in artificial intelligence research study that are based upon top-level symbolic (human-readable) representations of problems, logic and search. [3] Symbolic AI utilized tools such as reasoning programming, production rules, semantic webs and frames, and it developed applications such as knowledge-based systems (in particular, skilled systems), symbolic mathematics, automated theorem provers, ontologies, the semantic web, and automated preparation and scheduling systems. The Symbolic AI paradigm resulted in influential concepts in search, symbolic programs languages, agents, multi-agent systems, the semantic web, and the strengths and limitations of official understanding and thinking systems.
Symbolic AI was the dominant paradigm of AI research from the mid-1950s up until the mid-1990s. [4] Researchers in the 1960s and the 1970s were encouraged that symbolic approaches would eventually be successful in developing a maker with artificial general intelligence and considered this the supreme objective of their field. [citation needed] An early boom, with early successes such as the Logic Theorist and Samuel's Checkers Playing Program, caused unrealistic expectations and pledges and was followed by the first AI Winter as moneying dried up. [5] [6] A 2nd boom (1969-1986) took place with the increase of specialist systems, their guarantee of catching business know-how, and a passionate corporate welcome. [7] [8] That boom, and some early successes, e.g., with XCON at DEC, was followed once again by later on dissatisfaction. [8] Problems with problems in understanding acquisition, maintaining large understanding bases, and brittleness in managing out-of-domain problems emerged. Another, second, AI Winter (1988-2011) followed. [9] Subsequently, AI researchers concentrated on attending to underlying problems in handling unpredictability and in understanding acquisition. [10] Uncertainty was attended to with formal methods such as hidden Markov designs, Bayesian reasoning, and analytical relational learning. [11] [12] Symbolic maker discovering resolved the knowledge acquisition issue with contributions consisting of Version Space, Valiant's PAC knowing, Quinlan's ID3 decision-tree knowing, case-based learning, and inductive logic programming to find out relations. [13]
Neural networks, a subsymbolic method, had been pursued from early days and reemerged strongly in 2012. Early examples are Rosenblatt's perceptron learning work, the backpropagation work of Rumelhart, Hinton and Williams, [14] and operate in convolutional neural networks by LeCun et al. in 1989. [15] However, neural networks were not considered as successful until about 2012: "Until Big Data became prevalent, the basic agreement in the Al community was that the so-called neural-network technique was hopeless. Systems just didn't work that well, compared to other techniques. ... A revolution can be found in 2012, when a variety of people, including a group of scientists working with Hinton, worked out a method to utilize the power of GPUs to enormously increase the power of neural networks." [16] Over the next a number of years, deep knowing had magnificent success in managing vision, speech recognition, speech synthesis, image generation, and machine translation. However, because 2020, as intrinsic troubles with bias, description, coherence, and toughness ended up being more evident with deep learning methods; an increasing number of AI researchers have actually required integrating the very best of both the symbolic and neural network methods [17] [18] and resolving locations that both methods have problem with, such as sensible thinking. [16]
A brief history of symbolic AI to today day follows below. Time durations and titles are drawn from Henry Kautz's 2020 AAAI Robert S. Engelmore Memorial Lecture [19] and the longer Wikipedia article on the History of AI, with dates and titles differing a little for increased clarity.
The first AI summertime: irrational spirit, 1948-1966
Success at early efforts in AI happened in three main locations: artificial neural networks, understanding representation, and heuristic search, contributing to high expectations. This area summarizes Kautz's reprise of early AI history.
Approaches influenced by human or animal cognition or behavior
Cybernetic approaches tried to duplicate the feedback loops in between animals and their environments. A robotic turtle, with sensors, motors for driving and guiding, and seven vacuum tubes for control, based on a preprogrammed neural web, was constructed as early as 1948. This work can be viewed as an early precursor to later work in neural networks, reinforcement learning, and positioned robotics. [20]
A crucial early symbolic AI program was the Logic theorist, written by Allen Newell, Herbert Simon and Cliff Shaw in 1955-56, as it had the ability to show 38 primary theorems from Whitehead and Russell's Principia Mathematica. Newell, Simon, and Shaw later on generalized this work to develop a domain-independent problem solver, GPS (General Problem Solver). GPS solved issues represented with formal operators through state-space search utilizing means-ends analysis. [21]
During the 1960s, symbolic approaches achieved terrific success at imitating smart habits in structured environments such as game-playing, symbolic mathematics, and theorem-proving. AI research study was concentrated in 4 organizations in the 1960s: Carnegie Mellon University, Stanford, MIT and (later on) University of Edinburgh. Every one established its own design of research. Earlier approaches based on cybernetics or artificial neural networks were deserted or pushed into the background.
Herbert Simon and Allen Newell studied human analytical skills and tried to formalize them, and their work laid the foundations of the field of expert system, along with cognitive science, operations research study and management science. Their research study group utilized the results of mental experiments to establish programs that simulated the methods that people used to resolve problems. [22] [23] This tradition, centered at Carnegie Mellon University would ultimately culminate in the development of the Soar architecture in the middle 1980s. [24] [25]
Heuristic search
In addition to the extremely specialized domain-specific kinds of understanding that we will see later on utilized in professional systems, early symbolic AI researchers discovered another more general application of understanding. These were called heuristics, guidelines that direct a search in appealing instructions: "How can non-enumerative search be practical when the underlying problem is tremendously hard? The approach promoted by Simon and Newell is to employ heuristics: quick algorithms that might stop working on some inputs or output suboptimal options." [26] Another important advance was to discover a way to apply these heuristics that guarantees an option will be discovered, if there is one, not holding up against the periodic fallibility of heuristics: "The A * algorithm offered a general frame for complete and ideal heuristically directed search. A * is utilized as a subroutine within virtually every AI algorithm today but is still no magic bullet; its guarantee of efficiency is purchased the cost of worst-case rapid time. [26]
Early deal with understanding representation and thinking
Early work covered both applications of official thinking stressing first-order reasoning, together with attempts to manage common-sense thinking in a less formal way.
Modeling formal reasoning with logic: the "neats"
Unlike Simon and Newell, John McCarthy felt that devices did not need to replicate the precise systems of human idea, but might rather search for the essence of abstract thinking and analytical with reasoning, [27] no matter whether individuals used the exact same algorithms. [a] His lab at Stanford (SAIL) concentrated on using formal logic to resolve a wide array of problems, including understanding representation, planning and learning. [31] Logic was likewise the focus of the work at the University of Edinburgh and somewhere else in Europe which led to the advancement of the programs language Prolog and the science of logic programming. [32] [33]
Modeling implicit sensible knowledge with frames and scripts: the "scruffies"
Researchers at MIT (such as Marvin Minsky and Seymour Papert) [34] [35] [6] found that resolving tough problems in vision and natural language processing required advertisement hoc solutions-they argued that no basic and basic concept (like reasoning) would record all the elements of smart habits. Roger Schank explained their "anti-logic" techniques as "scruffy" (instead of the "cool" paradigms at CMU and Stanford). [36] [37] Commonsense understanding bases (such as Doug Lenat's Cyc) are an example of "shabby" AI, because they should be built by hand, one complicated principle at a time. [38] [39] [40]
The first AI winter season: crushed dreams, 1967-1977
The very first AI winter was a shock:
During the first AI summer, lots of people believed that device intelligence might be attained in simply a couple of years. The Defense Advance Research Projects Agency (DARPA) launched programs to support AI research study to use AI to fix issues of nationwide security; in particular, to automate the translation of Russian to English for intelligence operations and to develop autonomous tanks for the battleground. Researchers had actually started to understand that achieving AI was going to be much harder than was supposed a years earlier, but a combination of hubris and disingenuousness led lots of university and think-tank scientists to accept financing with promises of deliverables that they need to have understood they might not meet. By the mid-1960s neither helpful natural language translation systems nor autonomous tanks had actually been produced, and a dramatic backlash embeded in. New DARPA leadership canceled existing AI funding programs.
Beyond the United States, the most fertile ground for AI research study was the UK. The AI winter season in the UK was spurred on not so much by disappointed military leaders as by competing academics who saw AI researchers as charlatans and a drain on research study funding. A teacher of applied mathematics, Sir James Lighthill, was commissioned by Parliament to examine the state of AI research in the country. The report specified that all of the problems being worked on in AI would be better dealt with by researchers from other disciplines-such as applied mathematics. The report also claimed that AI successes on toy problems could never ever scale to real-world applications due to combinatorial explosion. [41]
The second AI summertime: knowledge is power, 1978-1987
Knowledge-based systems
As constraints with weak, domain-independent approaches ended up being increasingly more obvious, [42] scientists from all three traditions started to develop knowledge into AI applications. [43] [7] The understanding revolution was driven by the awareness that understanding underlies high-performance, domain-specific AI applications.
Edward Feigenbaum said:
- "In the knowledge lies the power." [44]
to explain that high efficiency in a particular domain needs both general and extremely domain-specific knowledge. Ed Feigenbaum and Doug Lenat called this The Knowledge Principle:
( 1) The Knowledge Principle: if a program is to perform a complicated job well, it should know a good deal about the world in which it operates.
( 2) A plausible extension of that concept, called the Breadth Hypothesis: there are 2 extra abilities required for intelligent behavior in unanticipated situations: falling back on progressively general understanding, and analogizing to particular however remote understanding. [45]
Success with professional systems
This "understanding revolution" led to the advancement and implementation of professional systems (introduced by Edward Feigenbaum), the very first commercially successful type of AI software application. [46] [47] [48]
Key specialist systems were:
DENDRAL, which found the structure of natural particles from their chemical formula and mass spectrometer readings.
MYCIN, which detected bacteremia - and suggested additional laboratory tests, when required - by analyzing laboratory results, patient history, and medical professional observations. "With about 450 rules, MYCIN was able to carry out along with some experts, and considerably much better than junior doctors." [49] INTERNIST and CADUCEUS which tackled internal medication medical diagnosis. Internist attempted to catch the know-how of the chairman of internal medication at the University of Pittsburgh School of Medicine while CADUCEUS might ultimately identify approximately 1000 various diseases.
- GUIDON, which demonstrated how an understanding base developed for expert problem resolving could be repurposed for teaching. [50] XCON, to configure VAX computers, a then laborious procedure that could use up to 90 days. XCON minimized the time to about 90 minutes. [9]
DENDRAL is thought about the very first professional system that relied on knowledge-intensive analytical. It is explained listed below, by Ed Feigenbaum, from a Communications of the ACM interview, Interview with Ed Feigenbaum:
Among the people at Stanford interested in computer-based models of mind was Joshua Lederberg, the 1958 Nobel Prize winner in genetics. When I told him I desired an induction "sandbox", he stated, "I have simply the one for you." His laboratory was doing mass spectrometry of amino acids. The question was: how do you go from taking a look at the spectrum of an amino acid to the chemical structure of the amino acid? That's how we started the DENDRAL Project: I was proficient at heuristic search methods, and he had an algorithm that was proficient at producing the chemical issue area.
We did not have a grandiose vision. We worked bottom up. Our chemist was Carl Djerassi, innovator of the chemical behind the birth control tablet, and also one of the world's most appreciated mass spectrometrists. Carl and his postdocs were first-rate specialists in mass spectrometry. We started to contribute to their knowledge, developing knowledge of engineering as we went along. These experiments totaled up to titrating DENDRAL increasingly more knowledge. The more you did that, the smarter the program ended up being. We had really great results.
The generalization was: in the understanding lies the power. That was the big idea. In my profession that is the huge, "Ah ha!," and it wasn't the method AI was being done previously. Sounds simple, however it's probably AI's most powerful generalization. [51]
The other professional systems discussed above came after DENDRAL. MYCIN exemplifies the timeless expert system architecture of a knowledge-base of guidelines combined to a symbolic thinking system, consisting of making use of certainty aspects to deal with unpredictability. GUIDON reveals how a specific knowledge base can be repurposed for a second application, tutoring, and is an example of a smart tutoring system, a specific sort of knowledge-based application. Clancey showed that it was not sufficient merely to utilize MYCIN's rules for guideline, however that he also required to include rules for discussion management and trainee modeling. [50] XCON is considerable because of the millions of dollars it saved DEC, which activated the specialist system boom where most all significant corporations in the US had professional systems groups, to record business proficiency, preserve it, and automate it:
By 1988, DEC's AI group had 40 specialist systems deployed, with more on the way. DuPont had 100 in use and 500 in advancement. Nearly every major U.S. corporation had its own Al group and was either utilizing or examining professional systems. [49]
Chess professional knowledge was encoded in Deep Blue. In 1996, this enabled IBM's Deep Blue, with the aid of symbolic AI, to win in a video game of chess against the world champ at that time, Garry Kasparov. [52]
Architecture of knowledge-based and expert systems
A crucial part of the system architecture for all specialist systems is the understanding base, which stores realities and rules for analytical. [53] The simplest method for a professional system knowledge base is just a collection or network of production rules. Production guidelines connect signs in a relationship similar to an If-Then statement. The expert system processes the guidelines to make deductions and to determine what additional details it requires, i.e. what concerns to ask, utilizing human-readable signs. For example, OPS5, CLIPS and their successors Jess and Drools operate in this style.
Expert systems can run in either a forward chaining - from evidence to conclusions - or backward chaining - from goals to required information and prerequisites - way. Advanced knowledge-based systems, such as Soar can also carry out meta-level thinking, that is reasoning about their own thinking in terms of deciding how to resolve problems and monitoring the success of problem-solving strategies.
Blackboard systems are a second kind of knowledge-based or skilled system architecture. They design a neighborhood of professionals incrementally contributing, where they can, to resolve a problem. The problem is represented in several levels of abstraction or alternate views. The professionals (understanding sources) offer their services whenever they acknowledge they can contribute. Potential problem-solving actions are represented on a program that is upgraded as the problem circumstance modifications. A controller decides how beneficial each contribution is, and who need to make the next analytical action. One example, the BB1 chalkboard architecture [54] was initially motivated by studies of how people plan to perform numerous tasks in a trip. [55] A development of BB1 was to use the exact same blackboard design to resolving its control issue, i.e., its controller carried out meta-level thinking with knowledge sources that kept track of how well a plan or the analytical was proceeding and might change from one strategy to another as conditions - such as objectives or times - altered. BB1 has been used in several domains: construction website preparation, intelligent tutoring systems, and real-time patient monitoring.
The second AI winter season, 1988-1993
At the height of the AI boom, companies such as Symbolics, LMI, and Texas Instruments were selling LISP machines particularly targeted to accelerate the development of AI applications and research. In addition, a number of synthetic intelligence business, such as Teknowledge and Inference Corporation, were offering professional system shells, training, and consulting to corporations.
Unfortunately, the AI boom did not last and Kautz finest explains the second AI winter season that followed:
Many factors can be used for the arrival of the second AI winter season. The hardware business failed when much more cost-efficient general Unix workstations from Sun together with excellent compilers for LISP and Prolog came onto the marketplace. Many business deployments of specialist systems were discontinued when they proved too pricey to preserve. Medical expert systems never caught on for several reasons: the trouble in keeping them approximately date; the challenge for medical specialists to discover how to utilize an overwelming variety of different specialist systems for different medical conditions; and maybe most crucially, the reluctance of doctors to rely on a computer-made diagnosis over their gut impulse, even for particular domains where the specialist systems might surpass an average physician. Equity capital cash deserted AI virtually overnight. The world AI conference IJCAI hosted an enormous and extravagant trade convention and thousands of nonacademic participants in 1987 in Vancouver; the main AI conference the following year, AAAI 1988 in St. Paul, was a little and strictly scholastic affair. [9]
Including more extensive foundations, 1993-2011
Uncertain thinking
Both analytical techniques and extensions to logic were tried.
One analytical approach, concealed Markov models, had actually already been popularized in the 1980s for speech recognition work. [11] Subsequently, in 1988, Judea Pearl popularized using Bayesian Networks as a sound but efficient method of handling uncertain reasoning with his publication of the book Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. [56] and Bayesian techniques were applied effectively in specialist systems. [57] Even later on, in the 1990s, statistical relational knowing, a technique that combines probability with sensible solutions, enabled probability to be combined with first-order reasoning, e.g., with either Markov Logic Networks or Probabilistic Soft Logic.
Other, non-probabilistic extensions to first-order logic to assistance were likewise attempted. For example, non-monotonic reasoning might be utilized with truth upkeep systems. A reality upkeep system tracked presumptions and reasons for all inferences. It enabled inferences to be withdrawn when presumptions were discovered to be inaccurate or a contradiction was obtained. Explanations might be attended to an inference by discussing which guidelines were used to create it and then continuing through underlying reasonings and rules all the way back to root presumptions. [58] Lofti Zadeh had presented a different type of extension to handle the representation of ambiguity. For instance, in choosing how "heavy" or "tall" a male is, there is frequently no clear "yes" or "no" answer, and a predicate for heavy or tall would instead return worths in between 0 and 1. Those worths represented to what degree the predicates held true. His fuzzy logic further offered a means for propagating mixes of these values through logical formulas. [59]
Artificial intelligence
Symbolic device learning approaches were examined to attend to the understanding acquisition traffic jam. Among the earliest is Meta-DENDRAL. Meta-DENDRAL utilized a generate-and-test strategy to produce plausible guideline hypotheses to evaluate against spectra. Domain and job understanding reduced the number of prospects tested to a manageable size. Feigenbaum explained Meta-DENDRAL as
... the culmination of my imagine the early to mid-1960s relating to theory formation. The conception was that you had an issue solver like DENDRAL that took some inputs and produced an output. In doing so, it used layers of understanding to steer and prune the search. That knowledge acted since we spoke with individuals. But how did individuals get the understanding? By looking at thousands of spectra. So we desired a program that would look at countless spectra and presume the understanding of mass spectrometry that DENDRAL might use to solve specific hypothesis formation issues. We did it. We were even able to publish new knowledge of mass spectrometry in the Journal of the American Chemical Society, providing credit only in a footnote that a program, Meta-DENDRAL, in fact did it. We had the ability to do something that had actually been a dream: to have a computer program created a brand-new and publishable piece of science. [51]
In contrast to the knowledge-intensive method of Meta-DENDRAL, Ross Quinlan developed a domain-independent technique to analytical classification, choice tree learning, beginning first with ID3 [60] and after that later on extending its abilities to C4.5. [61] The decision trees produced are glass box, interpretable classifiers, with human-interpretable category rules.
Advances were made in comprehending artificial intelligence theory, too. Tom Mitchell presented version space knowing which explains knowing as an explore a space of hypotheses, with upper, more basic, and lower, more particular, limits including all viable hypotheses constant with the examples seen so far. [62] More formally, Valiant presented Probably Approximately Correct Learning (PAC Learning), a structure for the mathematical analysis of artificial intelligence. [63]
Symbolic device finding out encompassed more than finding out by example. E.g., John Anderson supplied a cognitive model of human learning where ability practice results in a compilation of rules from a declarative format to a procedural format with his ACT-R cognitive architecture. For example, a trainee might discover to use "Supplementary angles are two angles whose steps sum 180 degrees" as numerous various procedural rules. E.g., one rule may state that if X and Y are supplemental and you know X, then Y will be 180 - X. He called his approach "knowledge compilation". ACT-R has been used successfully to design aspects of human cognition, such as finding out and retention. ACT-R is likewise used in intelligent tutoring systems, called cognitive tutors, to effectively teach geometry, computer system programming, and algebra to school children. [64]
Inductive logic shows was another approach to discovering that enabled logic programs to be manufactured from input-output examples. E.g., Ehud Shapiro's MIS (Model Inference System) could manufacture Prolog programs from examples. [65] John R. Koza used genetic algorithms to program synthesis to develop genetic programs, which he used to synthesize LISP programs. Finally, Zohar Manna and Richard Waldinger provided a more general method to program synthesis that synthesizes a practical program in the course of proving its specs to be right. [66]
As an option to logic, Roger Schank presented case-based reasoning (CBR). The CBR approach outlined in his book, Dynamic Memory, [67] focuses first on remembering crucial problem-solving cases for future usage and generalizing them where proper. When confronted with a brand-new problem, CBR retrieves the most comparable previous case and adjusts it to the specifics of the current issue. [68] Another alternative to logic, genetic algorithms and hereditary shows are based upon an evolutionary design of knowing, where sets of guidelines are encoded into populations, the guidelines govern the habits of individuals, and selection of the fittest prunes out sets of inappropriate guidelines over lots of generations. [69]
Symbolic artificial intelligence was used to finding out ideas, guidelines, heuristics, and analytical. Approaches, other than those above, include:
1. Learning from instruction or advice-i.e., taking human instruction, postured as recommendations, and identifying how to operationalize it in particular circumstances. For example, in a video game of Hearts, finding out exactly how to play a hand to "prevent taking points." [70] 2. Learning from exemplars-improving efficiency by accepting subject-matter specialist (SME) feedback throughout training. When problem-solving stops working, querying the expert to either learn a brand-new prototype for problem-solving or to find out a new explanation as to exactly why one exemplar is more relevant than another. For instance, the program Protos discovered to identify tinnitus cases by communicating with an audiologist. [71] 3. Learning by analogy-constructing issue services based on comparable problems seen in the past, and then modifying their options to fit a brand-new circumstance or domain. [72] [73] 4. Apprentice knowing systems-learning unique solutions to problems by observing human problem-solving. Domain knowledge discusses why unique solutions are correct and how the solution can be generalized. LEAP learned how to create VLSI circuits by observing human designers. [74] 5. Learning by discovery-i.e., developing jobs to carry out experiments and after that gaining from the results. Doug Lenat's Eurisko, for example, discovered heuristics to beat human players at the Traveller role-playing game for 2 years in a row. [75] 6. Learning macro-operators-i.e., looking for helpful macro-operators to be learned from series of fundamental problem-solving actions. Good macro-operators streamline problem-solving by allowing problems to be resolved at a more abstract level. [76]
Deep learning and neuro-symbolic AI 2011-now
With the rise of deep knowing, the symbolic AI approach has been compared to deep learning as complementary "... with parallels having actually been drawn often times by AI researchers in between Kahneman's research on human thinking and decision making - shown in his book Thinking, Fast and Slow - and the so-called "AI systems 1 and 2", which would in concept be modelled by deep knowing and symbolic thinking, respectively." In this view, symbolic thinking is more apt for deliberative reasoning, preparation, and explanation while deep learning is more apt for quick pattern acknowledgment in affective applications with loud information. [17] [18]
Neuro-symbolic AI: integrating neural and symbolic methods
Neuro-symbolic AI efforts to integrate neural and symbolic architectures in a way that addresses strengths and weaknesses of each, in a complementary style, in order to support robust AI capable of thinking, discovering, and cognitive modeling. As argued by Valiant [77] and lots of others, [78] the reliable construction of abundant computational cognitive models requires the mix of sound symbolic thinking and efficient (maker) learning models. Gary Marcus, likewise, argues that: "We can not construct rich cognitive designs in a sufficient, automatic method without the triune of hybrid architecture, abundant anticipation, and advanced techniques for reasoning.", [79] and in particular: "To develop a robust, knowledge-driven method to AI we must have the machinery of symbol-manipulation in our toolkit. Excessive of useful understanding is abstract to make do without tools that represent and control abstraction, and to date, the only equipment that we understand of that can control such abstract understanding dependably is the apparatus of symbol manipulation. " [80]
Henry Kautz, [19] Francesca Rossi, [81] and Bart Selman [82] have likewise argued for a synthesis. Their arguments are based upon a requirement to deal with the two type of believing discussed in Daniel Kahneman's book, Thinking, Fast and Slow. Kahneman explains human thinking as having 2 components, System 1 and System 2. System 1 is quickly, automatic, instinctive and unconscious. System 2 is slower, step-by-step, and explicit. System 1 is the kind utilized for pattern recognition while System 2 is far better suited for preparation, deduction, and deliberative thinking. In this view, deep knowing finest designs the first sort of believing while symbolic reasoning best models the 2nd kind and both are required.
Garcez and Lamb explain research study in this area as being ongoing for at least the past twenty years, [83] dating from their 2002 book on neurosymbolic knowing systems. [84] A series of workshops on neuro-symbolic thinking has been held every year considering that 2005, see http://www.neural-symbolic.org/ for details.
In their 2015 paper, Neural-Symbolic Learning and Reasoning: Contributions and Challenges, Garcez et al. argue that:
The integration of the symbolic and connectionist paradigms of AI has actually been pursued by a fairly little research study neighborhood over the last 2 years and has yielded numerous considerable results. Over the last years, neural symbolic systems have been shown efficient in getting rid of the so-called propositional fixation of neural networks, as McCarthy (1988) put it in reaction to Smolensky (1988 ); see also (Hinton, 1990). Neural networks were shown capable of representing modal and temporal logics (d'Avila Garcez and Lamb, 2006) and pieces of first-order logic (Bader, Hitzler, Hölldobler, 2008; d'Avila Garcez, Lamb, Gabbay, 2009). Further, neural-symbolic systems have actually been applied to a number of issues in the locations of bioinformatics, control engineering, software confirmation and adjustment, visual intelligence, ontology knowing, and computer games. [78]
Approaches for integration are differed. Henry Kautz's taxonomy of neuro-symbolic architectures, along with some examples, follows:
- Symbolic Neural symbolic-is the current technique of many neural designs in natural language processing, where words or subword tokens are both the supreme input and output of big language models. Examples include BERT, RoBERTa, and GPT-3.
- Symbolic [Neural] -is exemplified by AlphaGo, where symbolic strategies are used to call neural methods. In this case the symbolic approach is Monte Carlo tree search and the neural techniques discover how to evaluate game positions.
- Neural|Symbolic-uses a neural architecture to analyze affective data as signs and relationships that are then reasoned about symbolically.
- Neural: Symbolic → Neural-relies on symbolic reasoning to produce or identify training information that is consequently discovered by a deep knowing design, e.g., to train a neural model for symbolic computation by utilizing a Macsyma-like symbolic mathematics system to develop or identify examples.
- Neural _ Symbolic -uses a neural web that is produced from symbolic guidelines. An example is the Neural Theorem Prover, [85] which constructs a neural network from an AND-OR proof tree created from understanding base rules and terms. Logic Tensor Networks [86] likewise fall into this classification.
- Neural [Symbolic] -allows a neural design to straight call a symbolic thinking engine, e.g., to perform an action or assess a state.
Many key research concerns remain, such as:
- What is the very best way to incorporate neural and symbolic architectures? [87]- How should symbolic structures be represented within neural networks and extracted from them?
- How should sensible knowledge be discovered and reasoned about?
- How can abstract understanding that is tough to encode rationally be handled?
Techniques and contributions
This area offers an introduction of methods and contributions in a total context leading to many other, more comprehensive posts in Wikipedia. Sections on Artificial Intelligence and Uncertain Reasoning are covered previously in the history section.
AI shows languages
The key AI shows language in the US during the last symbolic AI boom period was LISP. LISP is the second oldest programming language after FORTRAN and was created in 1958 by John McCarthy. LISP offered the very first read-eval-print loop to support fast program development. Compiled functions might be freely mixed with translated functions. Program tracing, stepping, and breakpoints were likewise supplied, together with the capability to change worths or functions and continue from breakpoints or errors. It had the very first self-hosting compiler, meaning that the compiler itself was originally written in LISP and after that ran interpretively to assemble the compiler code.
Other key innovations originated by LISP that have spread to other programming languages include:
Garbage collection
Dynamic typing
Higher-order functions
Recursion
Conditionals
Programs were themselves data structures that other programs could operate on, allowing the simple meaning of higher-level languages.
In contrast to the US, in Europe the key AI shows language throughout that very same period was Prolog. Prolog offered an integrated shop of facts and provisions that might be queried by a read-eval-print loop. The shop could act as an understanding base and the clauses could act as guidelines or a restricted form of reasoning. As a subset of first-order reasoning Prolog was based on Horn provisions with a closed-world assumption-any realities not known were considered false-and a distinct name presumption for primitive terms-e.g., the identifier barack_obama was considered to describe precisely one object. Backtracking and marriage are built-in to Prolog.
Alain Colmerauer and Philippe Roussel are credited as the inventors of Prolog. Prolog is a type of logic programming, which was developed by Robert Kowalski. Its history was likewise affected by Carl Hewitt's PLANNER, an assertional database with pattern-directed invocation of approaches. For more information see the section on the origins of Prolog in the PLANNER short article.
Prolog is likewise a sort of declarative shows. The reasoning provisions that describe programs are straight analyzed to run the programs defined. No specific series of actions is needed, as holds true with crucial programming languages.
Japan championed Prolog for its Fifth Generation Project, intending to develop unique hardware for high efficiency. Similarly, LISP makers were built to run LISP, however as the second AI boom turned to bust these business could not take on new workstations that might now run LISP or Prolog natively at equivalent speeds. See the history section for more information.
Smalltalk was another prominent AI shows language. For instance, it presented metaclasses and, along with Flavors and CommonLoops, affected the Common Lisp Object System, or (CLOS), that is now part of Common Lisp, the existing standard Lisp dialect. CLOS is a Lisp-based object-oriented system that enables numerous inheritance, in addition to incremental extensions to both classes and metaclasses, hence providing a run-time meta-object protocol. [88]
For other AI shows languages see this list of programming languages for synthetic intelligence. Currently, Python, a multi-paradigm programs language, is the most popular programs language, partially due to its extensive plan library that supports data science, natural language processing, and deep learning. Python includes a read-eval-print loop, functional aspects such as higher-order functions, and object-oriented programming that consists of metaclasses.
Search
Search occurs in many sort of problem solving, consisting of planning, restriction fulfillment, and playing video games such as checkers, chess, and go. The finest known AI-search tree search algorithms are breadth-first search, depth-first search, A *, and Monte Carlo Search. Key search algorithms for Boolean satisfiability are WalkSAT, conflict-driven provision learning, and the DPLL algorithm. For adversarial search when playing video games, alpha-beta pruning, branch and bound, and minimax were early contributions.
Knowledge representation and thinking
Multiple various techniques to represent understanding and then reason with those representations have actually been examined. Below is a quick summary of methods to knowledge representation and automated reasoning.
Knowledge representation
Semantic networks, conceptual charts, frames, and reasoning are all approaches to modeling understanding such as domain knowledge, analytical knowledge, and the semantic meaning of language. Ontologies model crucial principles and their relationships in a domain. Example ontologies are YAGO, WordNet, and DOLCE. DOLCE is an example of an upper ontology that can be used for any domain while WordNet is a lexical resource that can likewise be deemed an ontology. YAGO includes WordNet as part of its ontology, to align truths extracted from Wikipedia with WordNet synsets. The Disease Ontology is an example of a medical ontology presently being used.
Description logic is a logic for automated category of ontologies and for spotting irregular category information. OWL is a language utilized to represent ontologies with description reasoning. Protégé is an ontology editor that can check out in OWL ontologies and then examine consistency with deductive classifiers such as such as HermiT. [89]
First-order logic is more basic than description reasoning. The automated theorem provers gone over listed below can show theorems in first-order reasoning. Horn clause logic is more limited than first-order logic and is utilized in logic programs languages such as Prolog. Extensions to first-order reasoning consist of temporal logic, to manage time; epistemic logic, to reason about agent understanding; modal reasoning, to deal with possibility and need; and probabilistic logics to manage logic and probability together.
Automatic theorem proving
Examples of automated theorem provers for first-order reasoning are:
Prover9.
ACL2.
Vampire.
Prover9 can be used in combination with the Mace4 design checker. ACL2 is a theorem prover that can handle evidence by induction and is a descendant of the Boyer-Moore Theorem Prover, likewise understood as Nqthm.
Reasoning in knowledge-based systems
Knowledge-based systems have an explicit understanding base, usually of rules, to improve reusability across domains by separating procedural code and domain understanding. A separate reasoning engine procedures guidelines and includes, deletes, or customizes an understanding store.
Forward chaining inference engines are the most common, and are seen in CLIPS and OPS5. Backward chaining occurs in Prolog, where a more minimal logical representation is used, Horn Clauses. Pattern-matching, specifically unification, is utilized in Prolog.
A more versatile sort of analytical occurs when reasoning about what to do next occurs, rather than merely selecting one of the readily available actions. This sort of meta-level reasoning is used in Soar and in the BB1 chalkboard architecture.
Cognitive architectures such as ACT-R may have additional capabilities, such as the capability to assemble regularly utilized knowledge into higher-level portions.
Commonsense thinking
Marvin Minsky initially proposed frames as a method of analyzing typical visual scenarios, such as an office, and Roger Schank extended this concept to scripts for typical routines, such as dining out. Cyc has tried to capture beneficial common-sense understanding and has "micro-theories" to handle particular sort of domain-specific reasoning.
Qualitative simulation, such as Benjamin Kuipers's QSIM, [90] estimates human reasoning about naive physics, such as what takes place when we heat up a liquid in a pot on the stove. We expect it to heat and potentially boil over, even though we might not understand its temperature level, its boiling point, or other information, such as air pressure.
Similarly, Allen's temporal interval algebra is a simplification of thinking about time and Region Connection Calculus is a simplification of thinking about spatial relationships. Both can be fixed with restraint solvers.
Constraints and constraint-based thinking
Constraint solvers perform a more limited kind of reasoning than first-order reasoning. They can simplify sets of spatiotemporal constraints, such as those for RCC or Temporal Algebra, together with resolving other kinds of puzzle issues, such as Wordle, Sudoku, cryptarithmetic problems, and so on. Constraint logic programming can be used to solve scheduling issues, for example with constraint dealing with rules (CHR).
Automated preparation
The General Problem Solver (GPS) cast planning as analytical used means-ends analysis to develop strategies. STRIPS took a different method, seeing preparation as theorem proving. Graphplan takes a least-commitment approach to planning, instead of sequentially selecting actions from a preliminary state, working forwards, or an objective state if working backwards. Satplan is a technique to preparing where a preparation problem is decreased to a Boolean satisfiability problem.
Natural language processing
Natural language processing concentrates on dealing with language as information to perform jobs such as recognizing subjects without always understanding the intended significance. Natural language understanding, in contrast, constructs a meaning representation and uses that for additional processing, such as addressing questions.
Parsing, tokenizing, spelling correction, part-of-speech tagging, noun and verb phrase chunking are all elements of natural language processing long managed by symbolic AI, however given that improved by deep learning approaches. In symbolic AI, discourse representation theory and first-order logic have been used to represent sentence meanings. Latent semantic analysis (LSA) and specific semantic analysis also provided vector representations of files. In the latter case, vector components are interpretable as ideas called by Wikipedia posts.
New deep learning techniques based upon Transformer models have actually now eclipsed these earlier symbolic AI approaches and achieved state-of-the-art performance in natural language processing. However, Transformer models are opaque and do not yet produce human-interpretable semantic representations for sentences and files. Instead, they produce task-specific vectors where the significance of the vector parts is nontransparent.
Agents and multi-agent systems
Agents are autonomous systems embedded in an environment they view and act upon in some sense. Russell and Norvig's basic textbook on expert system is organized to show representative architectures of increasing elegance. [91] The sophistication of agents varies from basic reactive agents, to those with a model of the world and automated preparation abilities, perhaps a BDI representative, i.e., one with beliefs, desires, and objectives - or additionally a support learning design learned with time to select actions - approximately a mix of alternative architectures, such as a neuro-symbolic architecture [87] that consists of deep knowing for understanding. [92]
On the other hand, a multi-agent system consists of several agents that interact amongst themselves with some inter-agent interaction language such as Knowledge Query and Manipulation Language (KQML). The representatives need not all have the exact same internal architecture. Advantages of multi-agent systems consist of the capability to divide work amongst the agents and to increase fault tolerance when representatives are lost. Research issues consist of how agents reach agreement, distributed problem solving, multi-agent knowing, multi-agent preparation, and distributed restraint optimization.
Controversies emerged from at an early stage in symbolic AI, both within the field-e.g., between logicists (the pro-logic "neats") and non-logicists (the anti-logic "scruffies")- and between those who welcomed AI however turned down symbolic approaches-primarily connectionists-and those outside the field. Critiques from outside of the field were mainly from theorists, on intellectual grounds, however also from funding companies, especially throughout the 2 AI winters.
The Frame Problem: knowledge representation difficulties for first-order logic
Limitations were found in utilizing basic first-order logic to factor about vibrant domains. Problems were found both with concerns to mentioning the prerequisites for an action to be successful and in providing axioms for what did not alter after an action was carried out.
McCarthy and Hayes presented the Frame Problem in 1969 in the paper, "Some Philosophical Problems from the Standpoint of Artificial Intelligence." [93] An easy example occurs in "proving that one person could enter into conversation with another", as an axiom asserting "if a person has a telephone he still has it after searching for a number in the telephone directory" would be required for the reduction to prosper. Similar axioms would be needed for other domain actions to define what did not change.
A comparable issue, called the Qualification Problem, takes place in trying to mention the prerequisites for an action to be successful. A limitless number of pathological conditions can be envisioned, e.g., a banana in a tailpipe could prevent an automobile from running correctly.
McCarthy's technique to fix the frame issue was circumscription, a kind of non-monotonic logic where reductions could be made from actions that need just define what would alter while not having to clearly specify everything that would not alter. Other non-monotonic reasonings supplied truth upkeep systems that revised beliefs causing contradictions.
Other methods of managing more open-ended domains consisted of probabilistic reasoning systems and device learning to discover brand-new concepts and guidelines. McCarthy's Advice Taker can be considered as a motivation here, as it might incorporate brand-new knowledge supplied by a human in the kind of assertions or rules. For instance, experimental symbolic machine discovering systems explored the ability to take top-level natural language advice and to interpret it into domain-specific actionable rules.
Similar to the issues in managing dynamic domains, common-sense thinking is also difficult to record in formal reasoning. Examples of sensible thinking consist of implicit thinking about how people think or general understanding of daily events, objects, and living creatures. This type of understanding is taken for granted and not deemed noteworthy. Common-sense thinking is an open area of research and challenging both for symbolic systems (e.g., Cyc has attempted to record key parts of this knowledge over more than a years) and neural systems (e.g., self-driving cars that do not understand not to drive into cones or not to strike pedestrians strolling a bike).
McCarthy viewed his Advice Taker as having sensible, however his meaning of common-sense was various than the one above. [94] He defined a program as having good sense "if it immediately deduces for itself an adequately broad class of instant repercussions of anything it is told and what it already knows. "
Connectionist AI: philosophical difficulties and sociological disputes
Connectionist methods include earlier work on neural networks, [95] such as perceptrons; operate in the mid to late 80s, such as Danny Hillis's Connection Machine and Yann LeCun's advances in convolutional neural networks; to today's more innovative techniques, such as Transformers, GANs, and other work in deep learning.
Three philosophical positions [96] have actually been outlined amongst connectionists:
1. Implementationism-where connectionist architectures execute the abilities for symbolic processing,
2. Radical connectionism-where symbolic processing is turned down completely, and connectionist architectures underlie intelligence and are fully adequate to discuss it,
3. Moderate connectionism-where symbolic processing and connectionist architectures are deemed complementary and both are needed for intelligence
Olazaran, in his sociological history of the controversies within the neural network community, explained the moderate connectionism view as essentially compatible with present research study in neuro-symbolic hybrids:
The 3rd and last position I wish to take a look at here is what I call the moderate connectionist view, a more diverse view of the current debate between connectionism and symbolic AI. Among the scientists who has elaborated this position most explicitly is Andy Clark, a thinker from the School of Cognitive and Computing Sciences of the University of Sussex (Brighton, England). Clark protected hybrid (partly symbolic, partly connectionist) systems. He declared that (a minimum of) 2 type of theories are required in order to study and model cognition. On the one hand, for some information-processing tasks (such as pattern recognition) connectionism has benefits over symbolic designs. But on the other hand, for other cognitive processes (such as serial, deductive reasoning, and generative sign control processes) the symbolic paradigm uses appropriate models, and not only "approximations" (contrary to what extreme connectionists would claim). [97]
Gary Marcus has actually declared that the animus in the deep learning neighborhood against symbolic approaches now may be more sociological than philosophical:
To believe that we can simply abandon symbol-manipulation is to suspend shock.
And yet, for the many part, that's how most current AI proceeds. Hinton and many others have attempted difficult to banish signs altogether. The deep learning hope-seemingly grounded not a lot in science, but in a sort of historic grudge-is that intelligent habits will emerge purely from the confluence of huge data and deep knowing. Where classical computer systems and software application resolve jobs by defining sets of symbol-manipulating rules devoted to specific tasks, such as modifying a line in a word processor or carrying out a computation in a spreadsheet, neural networks usually attempt to fix jobs by statistical approximation and finding out from examples.
According to Marcus, Geoffrey Hinton and his colleagues have actually been vehemently "anti-symbolic":
When deep knowing reemerged in 2012, it was with a type of take-no-prisoners mindset that has identified the majority of the last years. By 2015, his hostility toward all things signs had fully crystallized. He provided a talk at an AI workshop at Stanford comparing symbols to aether, one of science's biggest errors.
...
Ever since, his anti-symbolic campaign has only increased in strength. In 2016, Yann LeCun, Bengio, and Hinton composed a manifesto for deep learning in among science's most essential journals, Nature. It closed with a direct attack on symbol manipulation, calling not for reconciliation but for straight-out replacement. Later, Hinton told a gathering of European Union leaders that investing any additional cash in symbol-manipulating techniques was "a huge error," likening it to investing in internal combustion engines in the period of electric cars. [98]
Part of these conflicts might be because of uncertain terms:
Turing award winner Judea Pearl provides a critique of device knowing which, regrettably, conflates the terms maker learning and deep learning. Similarly, when Geoffrey Hinton describes symbolic AI, the connotation of the term tends to be that of specialist systems dispossessed of any capability to learn. The usage of the terms needs information. Machine learning is not confined to association guideline mining, c.f. the body of work on symbolic ML and relational learning (the differences to deep learning being the option of representation, localist logical rather than distributed, and the non-use of gradient-based knowing algorithms). Equally, symbolic AI is not practically production guidelines composed by hand. A proper definition of AI concerns knowledge representation and reasoning, autonomous multi-agent systems, preparation and argumentation, along with learning. [99]
Situated robotics: the world as a design
Another review of symbolic AI is the embodied cognition method:
The embodied cognition method claims that it makes no sense to think about the brain separately: cognition occurs within a body, which is embedded in an environment. We require to study the system as a whole; the brain's operating exploits consistencies in its environment, consisting of the rest of its body. Under the embodied cognition method, robotics, vision, and other sensors become central, not peripheral. [100]
Rodney Brooks developed behavior-based robotics, one method to embodied cognition. Nouvelle AI, another name for this method, is considered as an alternative to both symbolic AI and connectionist AI. His approach declined representations, either symbolic or distributed, as not just unneeded, however as harmful. Instead, he created the subsumption architecture, a layered architecture for embodied agents. Each layer accomplishes a various function and must operate in the real life. For example, the first robot he explains in Intelligence Without Representation, has three layers. The bottom layer interprets sonar sensing units to avoid things. The middle layer triggers the robotic to wander around when there are no barriers. The top layer causes the robot to go to more far-off places for further exploration. Each layer can momentarily prevent or suppress a lower-level layer. He criticized AI scientists for defining AI issues for their systems, when: "There is no tidy division between understanding (abstraction) and reasoning in the real world." [101] He called his robots "Creatures" and each layer was "composed of a fixed-topology network of simple finite state devices." [102] In the Nouvelle AI approach, "First, it is vitally important to test the Creatures we develop in the real life; i.e., in the very same world that we humans inhabit. It is dreadful to fall into the temptation of testing them in a simplified world first, even with the finest objectives of later moving activity to an unsimplified world." [103] His emphasis on real-world testing remained in contrast to "Early operate in AI focused on games, geometrical issues, symbolic algebra, theorem proving, and other formal systems" [104] and the usage of the blocks world in symbolic AI systems such as SHRDLU.
Current views
Each approach-symbolic, connectionist, and behavior-based-has benefits, however has been slammed by the other methods. Symbolic AI has been criticized as disembodied, responsible to the credentials problem, and poor in dealing with the affective problems where deep learning excels. In turn, connectionist AI has actually been criticized as poorly suited for deliberative detailed issue resolving, including knowledge, and dealing with planning. Finally, Nouvelle AI excels in reactive and real-world robotics domains however has actually been slammed for problems in including knowing and understanding.
Hybrid AIs integrating several of these methods are presently deemed the course forward. [19] [81] [82] Russell and Norvig conclude that:
Overall, Dreyfus saw areas where AI did not have total responses and stated that Al is therefore impossible; we now see a number of these exact same areas undergoing continued research and development leading to increased capability, not impossibility. [100]
Artificial intelligence.
Automated planning and scheduling
Automated theorem proving
Belief revision
Case-based reasoning
Cognitive architecture
Cognitive science
Connectionism
Constraint shows
Deep learning
First-order logic
GOFAI
History of expert system
Inductive reasoning programming
Knowledge-based systems
Knowledge representation and thinking
Logic programming
Machine knowing
Model monitoring
Model-based reasoning
Multi-agent system
Natural language processing
Neuro-symbolic AI
Ontology
Philosophy of expert system
Physical symbol systems hypothesis
Semantic Web
Sequential pattern mining
Statistical relational learning
Symbolic mathematics
YAGO ontology
WordNet
Notes
^ McCarthy once stated: "This is AI, so we don't care if it's mentally real". [4] McCarthy restated his position in 2006 at the AI@50 conference where he said "Expert system is not, by meaning, simulation of human intelligence". [28] Pamela McCorduck composes that there are "2 major branches of synthetic intelligence: one targeted at producing smart behavior regardless of how it was accomplished, and the other focused on modeling smart processes discovered in nature, especially human ones.", [29] Stuart Russell and Peter Norvig composed "Aeronautical engineering texts do not define the objective of their field as making 'devices that fly so exactly like pigeons that they can deceive even other pigeons.'" [30] Citations
^ Garnelo, Marta; Shanahan, Murray (October 2019). "Reconciling deep knowing with symbolic expert system: representing objects and relations". Current Opinion in Behavioral Sciences. 29: 17-23. doi:10.1016/ j.cobeha.2018.12.010. hdl:10044/ 1/67796.
^ Thomason, Richmond (February 27, 2024). "Logic-Based Expert System". In Zalta, Edward N. (ed.). Stanford Encyclopedia of Philosophy.
^ Garnelo, Marta; Shanahan, Murray (2019-10-01). "Reconciling deep learning with symbolic expert system: representing objects and relations". Current Opinion in Behavioral Sciences. 29: 17-23. doi:10.1016/ j.cobeha.2018.12.010. hdl:10044/ 1/67796. S2CID 72336067.
^ a b Kolata 1982.
^ Kautz 2022, pp. 107-109.
^ a b Russell & Norvig 2021, p. 19.
^ a b Russell & Norvig 2021, pp. 22-23.
^ a b Kautz 2022, pp. 109-110.
^ a b c Kautz 2022, p. 110.
^ Kautz 2022, pp. 110-111.
^ a b Russell & Norvig 2021, p. 25.
^ Kautz 2022, p. 111.
^ Kautz 2020, pp. 110-111.
^ Rumelhart, David E.; Hinton, Geoffrey E.; Williams, Ronald J. (1986 ). "Learning representations by back-propagating mistakes". Nature. 323 (6088 ): 533-536. Bibcode:1986 Natur.323..533 R. doi:10.1038/ 323533a0. ISSN 1476-4687. S2CID 205001834.
^ LeCun, Y.; Boser, B.; Denker, I.; Henderson, D.; Howard, R.; Hubbard, W.; Tackel, L. (1989 ). "Backpropagation Applied to Handwritten Postal Code Recognition". Neural Computation. 1 (4 ): 541-551. doi:10.1162/ neco.1989.1.4.541. S2CID 41312633.
^ a b Marcus & Davis 2019.
^ a b Rossi, Francesca. "Thinking Fast and Slow in AI". AAAI. Retrieved 5 July 2022.
^ a b Selman, Bart. "AAAI Presidential Address: The State of AI". AAAI. Retrieved 5 July 2022.
^ a b c Kautz 2020.
^ Kautz 2022, p. 106.
^ Newell & Simon 1972.
^ & McCorduck 2004, pp. 139-179, 245-250, 322-323 (EPAM).
^ Crevier 1993, pp. 145-149.
^ McCorduck 2004, pp. 450-451.
^ Crevier 1993, pp. 258-263.
^ a b Kautz 2022, p. 108.
^ Russell & Norvig 2021, p. 9 (logicist AI), p. 19 (McCarthy's work).
^ Maker 2006.
^ McCorduck 2004, pp. 100-101.
^ Russell & Norvig 2021, p. 2.
^ McCorduck 2004, pp. 251-259.
^ Crevier 1993, pp. 193-196.
^ Howe 1994.
^ McCorduck 2004, pp. 259-305.
^ Crevier 1993, pp. 83-102, 163-176.
^ McCorduck 2004, pp. 421-424, 486-489.
^ Crevier 1993, p. 168.
^ McCorduck 2004, p. 489.
^ Crevier 1993, pp. 239-243.
^ Russell & Norvig 2021, p. 316, 340.
^ Kautz 2022, p. 109.
^ Russell & Norvig 2021, p. 22.
^ McCorduck 2004, pp. 266-276, 298-300, 314, 421.
^ Shustek, Len (June 2010). "An interview with Ed Feigenbaum". Communications of the ACM. 53 (6 ): 41-45. doi:10.1145/ 1743546.1743564. ISSN 0001-0782. S2CID 10239007. Retrieved 2022-07-14.
^ Lenat, Douglas B; Feigenbaum, Edward A (1988 ). "On the thresholds of understanding". Proceedings of the International Workshop on Expert System for Industrial Applications: 291-300. doi:10.1109/ AIIA.1988.13308. S2CID 11778085.
^ Russell & Norvig 2021, pp. 22-24.
^ McCorduck 2004, pp. 327-335, 434-435.
^ Crevier 1993, pp. 145-62, 197-203.
^ a b Russell & Norvig 2021, p. 23.
^ a b Clancey 1987.
^ a b Shustek, Len (2010 ). "An interview with Ed Feigenbaum". Communications of the ACM. 53 (6 ): 41-45. doi:10.1145/ 1743546.1743564. ISSN 0001-0782. S2CID 10239007. Retrieved 2022-08-05.
^ "The fascination with AI: what is artificial intelligence?". IONOS Digitalguide. Retrieved 2021-12-02.
^ Hayes-Roth, Murray & Adelman 2015.
^ Hayes-Roth, Barbara (1985 ). "A chalkboard architecture for control". Artificial Intelligence. 26 (3 ): 251-321. doi:10.1016/ 0004-3702( 85 )90063-3.
^ Hayes-Roth, Barbara (1980 ). Human Planning Processes. RAND.
^ Pearl 1988.
^ Spiegelhalter et al. 1993.
^ Russell & Norvig 2021, pp. 335-337.
^ Russell & Norvig 2021, p. 459.
^ Quinlan, J. Ross. "Chapter 15: Learning Efficient Classification Procedures and their Application to Chess End Games". In Michalski, Carbonell & Mitchell (1983 ).
^ Quinlan, J. Ross (1992-10-15). C4.5: Programs for Machine Learning (1st ed.). San Mateo, Calif: Morgan Kaufmann. ISBN 978-1-55860-238-0.
^ Mitchell, Tom M.; Utgoff, Paul E.; Banerji, Ranan. "Chapter 6: Learning by Experimentation: Acquiring and Refining Problem-Solving Heuristics". In Michalski, Carbonell & Mitchell (1983 ).
^ Valiant, L. G. (1984-11-05). "A theory of the learnable". Communications of the ACM. 27 (11 ): 1134-1142. doi:10.1145/ 1968.1972. ISSN 0001-0782. S2CID 12837541.
^ Koedinger, K. R.; Anderson, J. R.; Hadley, W. H.; Mark, M. A.; others (1997 ). "Intelligent tutoring goes to school in the big city". International Journal of Artificial Intelligence in Education (IJAIED). 8: 30-43. Retrieved 2012-08-18.
^ Shapiro, Ehud Y (1981 ). "The Model Inference System". Proceedings of the 7th global joint conference on Expert system. IJCAI. Vol. 2. p. 1064.
^ Manna, Zohar; Waldinger, Richard (1980-01-01). "A Deductive Approach to Program Synthesis". ACM Trans. Program. Lang. Syst. 2 (1 ): 90-121. doi:10.1145/ 357084.357090. S2CID 14770735.
^ Schank, Roger C. (1983-01-28). Dynamic Memory: A Theory of Reminding and Learning in Computers and People. Cambridge Cambridgeshire: New York: Cambridge University Press. ISBN 978-0-521-27029-8.
^ Hammond, Kristian J. (1989-04-11). Case-Based Planning: Viewing Planning as a Memory Task. Boston: Academic Press. ISBN 978-0-12-322060-8.
^ Koza, John R. (1992-12-11). Genetic Programming: On the Programming of Computers by Means of Natural Selection (1st ed.). Cambridge, Mass: A Bradford Book. ISBN 978-0-262-11170-6.
^ Mostow, David Jack. "Chapter 12: Machine Transformation of Advice into a Heuristic Search Procedure". In Michalski, Carbonell & Mitchell (1983 ).
^ Bareiss, Ray; Porter, Bruce; Wier, Craig. "Chapter 4: Protos: An Exemplar-Based Learning Apprentice". In Michalski, Carbonell & Mitchell (1986 ), pp. 112-139.
^ Carbonell, Jaime. "Chapter 5: Learning by Analogy: Formulating and Generalizing Plans from Past Experience". In Michalski, Carbonell & Mitchell (1983 ), pp. 137-162.
^ Carbonell, Jaime. "Chapter 14: Derivational Analogy: A Theory of Reconstructive Problem Solving and Expertise Acquisition". In Michalski, Carbonell & Mitchell (1986 ), pp. 371-392.
^ Mitchell, Tom; Mabadevan, Sridbar; Steinberg, Louis. "Chapter 10: LEAP: A Learning Apprentice for VLSI Design". In Kodratoff & Michalski (1990 ), pp. 271-289.
^ Lenat, Douglas. "Chapter 9: The Role of Heuristics in Learning by Discovery: Three Case Studies". In Michalski, Carbonell & Mitchell (1983 ), pp. 243-306.
^ Korf, Richard E. (1985 ). Learning to Solve Problems by Searching for Macro-Operators. Research Notes in Expert System. Pitman Publishing. ISBN 0-273-08690-1.
^ Valiant 2008.
^ a b Garcez et al. 2015.
^ Marcus 2020, p. 44.
^ Marcus 2020, p. 17.
^ a b Rossi 2022.
^ a b Selman 2022.
^ Garcez & Lamb 2020, p. 2.
^ Garcez et al. 2002.
^ Rocktäschel, Tim; Riedel, Sebastian (2016 ). "Learning Knowledge Base Inference with Neural Theorem Provers". Proceedings of the fifth Workshop on Automated Knowledge Base Construction. San Diego, CA: Association for Computational Linguistics. pp. 45-50. doi:10.18653/ v1/W16 -1309. Retrieved 2022-08-06.
^ Serafini, Luciano; Garcez, Artur d'Avila (2016 ), Logic Tensor Networks: Deep Learning and Logical Reasoning from Data and Knowledge, arXiv:1606.04422.
^ a b Garcez, Artur d'Avila; Lamb, Luis C.; Gabbay, Dov M. (2009 ). Neural-Symbolic Cognitive Reasoning (1st ed.). Berlin-Heidelberg: Springer. Bibcode:2009 nscr.book ... D. doi:10.1007/ 978-3-540-73246-4. ISBN 978-3-540-73245-7. S2CID 14002173.
^ Kiczales, Gregor; Rivieres, Jim des; Bobrow, Daniel G. (1991-07-30). The Art of the Metaobject Protocol (1st ed.). Cambridge, Mass: The MIT Press. ISBN 978-0-262-61074-2.
^ Motik, Boris; Shearer, Rob; Horrocks, Ian (2009-10-28). "Hypertableau Reasoning for Description Logics". Journal of Expert System Research. 36: 165-228. arXiv:1401.3485. doi:10.1613/ jair.2811. ISSN 1076-9757. S2CID 190609.
^ Kuipers, Benjamin (1994 ). Qualitative Reasoning: Modeling and Simulation with Incomplete Knowledge. MIT Press. ISBN 978-0-262-51540-5.
^ Russell & Norvig 2021.
^ Leo de Penning, Artur S. d'Avila Garcez, Luís C. Lamb, John-Jules Ch. Meyer: "A Neural-Symbolic Cognitive Agent for Online Learning and Reasoning." IJCAI 2011: 1653-1658.
^ McCarthy & Hayes 1969.
^ McCarthy 1959.
^ Nilsson 1998, p. 7.
^ Olazaran 1993, pp. 411-416.
^ Olazaran 1993, pp. 415-416.
^ Marcus 2020, p. 20.
^ Garcez & Lamb 2020, p. 8.
^ a b Russell & Norvig 2021, p. 982.
^ Brooks 1991, p. 143.
^ Brooks 1991, p. 151.
^ Brooks 1991, p. 150.
^ Brooks 1991, p. 142.
References
Brooks, Rodney A. (1991 ). "Intelligence without representation". Artificial Intelligence. 47 (1 ): 139-159. doi:10.1016/ 0004-3702( 91 )90053-M. ISSN 0004-3702. S2CID 207507849. Retrieved 2022-09-13.
Clancey, William (1987 ). Knowledge-Based Tutoring: The GUIDON Program (MIT Press Series in Expert System) (Hardcover ed.).
Crevier, Daniel (1993 ). AI: The Tumultuous Search for Artificial Intelligence. New York City, NY: BasicBooks. ISBN 0-465-02997-3.
Dreyfus, Hubert L (1981 ). "From micro-worlds to understanding representation: AI at an impasse" (PDF). Mind Design. MIT Press, Cambridge, MA: 161-204.
Garcez, Artur S. d'Avila; Broda, Krysia; Gabbay, Dov M.; Gabbay, Augustus de Morgan Professor of Logic Dov M. (2002 ). Neural-Symbolic Learning Systems: Foundations and Applications. Springer Science & Business Media. ISBN 978-1-85233-512-0.
Garcez, Artur; Besold, Tarek; De Raedt, Luc; Földiák, Peter; Hitzler, Pascal; Icard, Thomas; Kühnberger, Kai-Uwe; Lamb, Luís; Miikkulainen, Risto; Silver, Daniel (2015 ). Neural-Symbolic Learning and Reasoning: Contributions and Challenges. AAI Spring Symposium - Knowledge Representation and Reasoning: Integrating Symbolic and Neural Approaches. Stanford, CA: AAAI Press. doi:10.13140/ 2.1.1779.4243.
Garcez, Artur d'Avila; Gori, Marco; Lamb, Luis C.; Serafini, Luciano; Spranger, Michael; Tran, Son N. (2019 ), Neural-Symbolic Computing: An Efficient Methodology for Principled Integration of Artificial Intelligence and Reasoning, arXiv:1905.06088.
Garcez, Artur d'Avila; Lamb, Luis C. (2020 ), Neurosymbolic AI: The 3rd Wave, arXiv:2012.05876.
Haugeland, John (1985 ), Expert System: The Very Idea, Cambridge, Mass: MIT Press, ISBN 0-262-08153-9.
Hayes-Roth, Frederick; Murray, William; Adelman, Leonard (2015 ). "Expert systems". AccessScience. doi:10.1036/ 1097-8542.248550.
Honavar, Vasant; Uhr, Leonard (1994 ). Symbolic Expert System, Connectionist Networks & Beyond (Technical report). Iowa State University Digital Repository, Computer Science Technical Reports. 76. p. 6.
Honavar, Vasant (1995 ). Symbolic Artificial Intelligence and Numeric Artificial Neural Networks: Towards a Resolution of the Dichotomy. The Springer International Series In Engineering and Computer Technology. Springer US. pp. 351-388. doi:10.1007/ 978-0-585-29599-2_11.
Howe, J. (November 1994). "Artificial Intelligence at Edinburgh University: a Point of view". Archived from the original on 15 May 2007. Retrieved 30 August 2007.
Kautz, Henry (2020-02-11). The Third AI Summer, Henry Kautz, AAAI 2020 Robert S. Engelmore Memorial Award Lecture. Retrieved 2022-07-06.
Kautz, Henry (2022 ). "The Third AI Summer: AAAI Robert S. Engelmore Memorial Lecture". AI Magazine. 43 (1 ): 93-104. doi:10.1609/ aimag.v43i1.19122. ISSN 2371-9621. S2CID 248213051. Retrieved 2022-07-12.
Kodratoff, Yves; Michalski, Ryszard, eds. (1990 ). Artificial intelligence: an Artificial Intelligence Approach. Vol. III. San Mateo, Calif.: Morgan Kaufman. ISBN 0-934613-09-5. OCLC 893488404.
Kolata, G. (1982 ). "How can computers get sound judgment?". Science. 217 (4566 ): 1237-1238. Bibcode:1982 Sci ... 217.1237 K. doi:10.1126/ science.217.4566.1237. PMID 17837639.
Maker, Meg Houston (2006 ). "AI@50: AI Past, Present, Future". Dartmouth College. Archived from the original on 3 January 2007. Retrieved 16 October 2008.
Marcus, Gary; Davis, Ernest (2019 ). Rebooting AI: Building Expert System We Can Trust. New York: Pantheon Books. ISBN 9781524748258. OCLC 1083223029.
Marcus, Gary (2020 ), The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence, arXiv:2002.06177.
McCarthy, John (1959 ). PROGRAMS WITH SOUND JUDGMENT. Symposium on Mechanization of Thought Processes. NATIONAL PHYSICAL LABORATORY, TEDDINGTON, UK. p. 8.
McCarthy, John; Hayes, Patrick (1969 ). "Some Philosophical Problems From the Standpoint of Artificial Intelligence". Machine Intelligence 4. B. Meltzer, Donald Michie (eds.): 463-502.
McCorduck, Pamela (2004 ), Machines Who Think (second ed.), Natick, Massachusetts: A. K. Peters, ISBN 1-5688-1205-1.
Michalski, Ryszard; Carbonell, Jaime; Mitchell, Tom, eds. (1983 ). Machine Learning: an Artificial Intelligence Approach. Vol. I. Palo Alto, Calif.: Tioga Publishing Company. ISBN 0-935382-05-4. OCLC 9262069.
Michalski, Ryszard; Carbonell, Jaime; Mitchell, Tom, eds. (1986 ). Artificial intelligence: an Artificial Intelligence Approach. Vol. II. Los Altos, Calif.: Morgan Kaufman. ISBN 0-934613-00-1.
Newell, Allen; Simon, Herbert A. (1972 ). Human Problem Solving (1st ed.). Englewood Cliffs, New Jersey: Prentice Hall. ISBN 0-13-445403-0.
Newell, Allen; Simon, H. A. (1976 ). "Computer Technology as Empirical Inquiry: Symbols and Search". Communications of the ACM. 19 (3 ): 113-126. doi:10.1145/ 360018.360022.
Nilsson, Nils (1998 ). Expert system: A New Synthesis. Morgan Kaufmann. ISBN 978-1-55860-467-4. Archived from the original on 26 July 2020. Retrieved 18 November 2019.
Olazaran, Mikel (1993-01-01), "A Sociological History of the Neural Network Controversy", in Yovits, Marshall C. (ed.), Advances in Computers Volume 37, vol. 37, Elsevier, pp. 335-425, doi:10.1016/ S0065-2458( 08 )60408-8, ISBN 9780120121373, obtained 2023-10-31.
Pearl, J. (1988 ). Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. San Mateo, California: Morgan Kaufmann. ISBN 978-1-55860-479-7. OCLC 249625842.
Russell, Stuart J.; Norvig, Peter (2021 ). Expert system: A Modern Approach (4th ed.). Hoboken: Pearson. ISBN 978-0-13-461099-3. LCCN 20190474.
Rossi, Francesca (2022-07-06). "AAAI2022: Thinking Fast and Slow in AI (AAAI 2022 Invited Talk)". Retrieved 2022-07-06.
Selman, Bart (2022-07-06). "AAAI2022: Presidential Address: The State of AI". Retrieved 2022-07-06.
Serafini, Luciano; Garcez, Artur d'Avila (2016-07-07), Logic Tensor Networks: Deep Learning and Logical Reasoning from Data and Knowledge, arXiv:1606.04422.
Spiegelhalter, David J.; Dawid, A. Philip; Lauritzen, Steffen; Cowell, Robert G. (1993 ). "Bayesian analysis in expert systems". Statistical Science. 8 (3 ).
Turing, A. M. (1950 ). "I.-Computing Machinery and Intelligence". Mind. LIX (236 ): 433-460. doi:10.1093/ mind/LIX.236.433. ISSN 0026-4423. Retrieved 2022-09-14.
Valiant, Leslie G (2008 ). "Knowledge Infusion: In Pursuit of Robustness in Artificial Intelligence". In Hariharan, R.; Mukund, M.; Vinay, V. (eds.). Foundations of Software Technology and Theoretical Computer Science (Bangalore). pp. 415-422.
Xifan Yao; Jiajun Zhou; Jiangming Zhang; Claudio R. Boer (2017 ). From Intelligent Manufacturing to Smart Manufacturing for Industry 4.0 Driven by Next Generation Artificial Intelligence and Further On.
#3 Test forum » Italy Blocks Chinese Chatbot DeepSeek » 2025-02-01 11:29:55
- Darrin54C
- Replies: 0
The Italian regulator has blocked a Chinese application with integrated expert system DeepSeek.
This was reported by the local regulator Garante.
The emergency order entered impact right away to safeguard the personal information of Italians.
The decision comes two days after Italy sent a demand about how DeepSeek uses users' individual information. The local regulator asked what information is gathered, why, and whether it is saved in China. However, the Chinese business's action was deemed "entirely inadequate". They said they do not run in Italy which European law does not apply to them.
The DeepSeek app has actually been missing from digital shops in Italy because January 29. The web variation, however, remained offered - and it is still offered today.%20Is%20Used%20In%20Biometrics.jpg)
The Italian newspaper la Repubblica composes that the primary page of DeepSeek states that usersʼ personal information is stored on servers in China, the material of chats with the bot can be used to train its algorithms, and the service should not be used by kids under 14. However, the Italian regulator asked for extra information, which it did not receive.
What is DeepSeek?
On January 27, DeepSeek surpassed ChatGPT to become the most popular complimentary app on the App Store. On the exact same day, the Chinese chatbot was subjected to a massive cyberattack.
DeepSeek was founded in 2023 by Liang Wenfeng, a 40-year-old graduate of the School of Information and Electronic Engineering. He established a shop for Nvidia A100 chips, which are now prohibited from being exported to China. Media reports recommend that this may have triggered him to release DeepSeek, combining those chips with cheaper, lower-end ones that are still readily available for import.
DeepSeek is based on the open-source DeepSeek-V3 design. Some experts say that the design was developed for less than $6 million - rivals spend far more. However, other professionals dispute this details.
#4 Test forum » Making aI Helpful For Everyone » 2025-02-01 11:17:10
- Darrin54C
- Replies: 0
Google AI on Android reimagines your mobile device experience, helping you be more innovative, get more done, and remain safe with effective defense from Google. Just circle an image, text, or video to browse anything throughout your phone with Circle to Search * and find out more with AI overviews.
Just circle an image, text, or video to browse anything throughout your phone with Circle to Search * and find out more with AI overviews. Bring Gemini up over your screen to get aid with the content you're looking at without switching apps, or go Live to talk things out and brainstorm with Gemini. Make complex edits without pro-level editing skills, with Magic Editor.
Bring Gemini up over your screen to get aid with the content you're looking at without switching apps, or go Live to talk things out and brainstorm with Gemini. Make complex edits without pro-level editing skills, with Magic Editor. Enjoy a customized, smarter messaging experience with Magic Compose.
Enjoy a customized, smarter messaging experience with Magic Compose.
* Available on choose devices and internet connection required. Works on compatible apps and surfaces.
Works on compatible apps and surfaces. Results may differ depending on visual matches and are for illustrative purposes only. Sequences are shortened.
Results may differ depending on visual matches and are for illustrative purposes only. Sequences are shortened.
#5 Test forum » Tech Tycoons have Got the Economics of AI Wrong » 2025-02-01 11:11:51
- Darrin54C
- Replies: 0

Even as economic growth was simply taking off, some economists were currently downhearted. Coal, wrote William Stanley Jevons in 1865, is "the mainspring of modern-day material civilisation". Yet it was limited and would quickly go out. Although more might be found by digging deeper, it would be increasingly expensive to extract and these higher expenses would minimize the competitiveness of Britain's producers. After all, in other nations the black fuel was still in sight of daytime. Efficiency gains-using less coal to produce the same amount of stuff-would not save the nation. Indeed, cleverer use of restricted resources would simply supply a reward to burn much more coal, which would, paradoxically, lead to an even much faster use of British reserves. There was no escape, the Victorian economic expert thought. Coal would be exhausted and the nation was likely to "contract to her previous littleness".
Explore more
This post appeared in the Finance & economics section of the print edition under the heading "Rocked by DeepSeek"
Finance & economics February 1st 2025
Donald Trump's financial warfare has a brand-new front
Will America's crypto frenzy end in disaster?
Don't let Donald Trump see our Big Mac index
Giorgia Meloni has grand banking aspirations
Can Germany's economy stage an unanticipated healing?
Why your portfolio is less varied than you might believe
Tech magnates have got the economics of AI wrong
From the February 1st 2025 edition
Discover stories from this area and more in the list of contents
More from Finance & economics
Why your portfolio is less diversified than you may think
The most important idea in modern-day financing has ended up being maddeningly difficult to implement
Can Germany's economy stage an unexpected recovery?
The situation is alarming, however there are twinkles of hope
Giorgia Meloni has grand banking aspirations
Will Italy's nationalist prime minister handle to concentrate financial power?
Donald Trump's economic warfare has a new front
The president has actually threatened to explode the worldwide tax system. Will allies have the ability to stop him?
#6 Test forum » Everyday Examples and Applications Of Expert System (AI). » 2025-02-01 10:55:08
- Darrin54C
- Replies: 0
You have actually probably heard of self-driving cars and trucks, whether in a sci-fi program or in the news from current efforts by various companies.
 Most significant map software application uses some sort of AI to analyze real-time traffic data and provide paths and ETAs.
Most significant map software application uses some sort of AI to analyze real-time traffic data and provide paths and ETAs. Additionally, numerous aircraft utilize an AI-powered autopilot that takes in climate condition and flight data to set the course.
Additionally, numerous aircraft utilize an AI-powered autopilot that takes in climate condition and flight data to set the course.
In truth, studies show that the application of AI in transport has made it more secure, more effective, and more reliable.
Other examples of AI in transport and navigation consist of:
Traffic management systems take in real-time information about the road, weather condition, and traffic conditions to anticipate heavier traffic flows and congestion.
Direction apps such as Google Maps, Apple Maps, and Waze all use place data gathered from users to figure out traffic, ETAs, and more.![]()
Rideshare apps, similar to direction apps, use AI that takes in area and ecological data to offer ETAs, predict road conditions, and set fare rates.
#7 Test forum » But DeepSeek May be Even Worse » 2025-02-01 10:14:24
- Darrin54C
- Replies: 0

An inexpensive AI-powered chatbot from China has actually sent out shockwaves around the globe, causing panic for Western tech firms who believed they were jumps ahead in the expert system race.
The DeepSeek model competitors OpenAI's ChatGPT - however is said to have been developed for just ₤ 4.8 million compared to the latter's cost of upwards of ₤ 80million.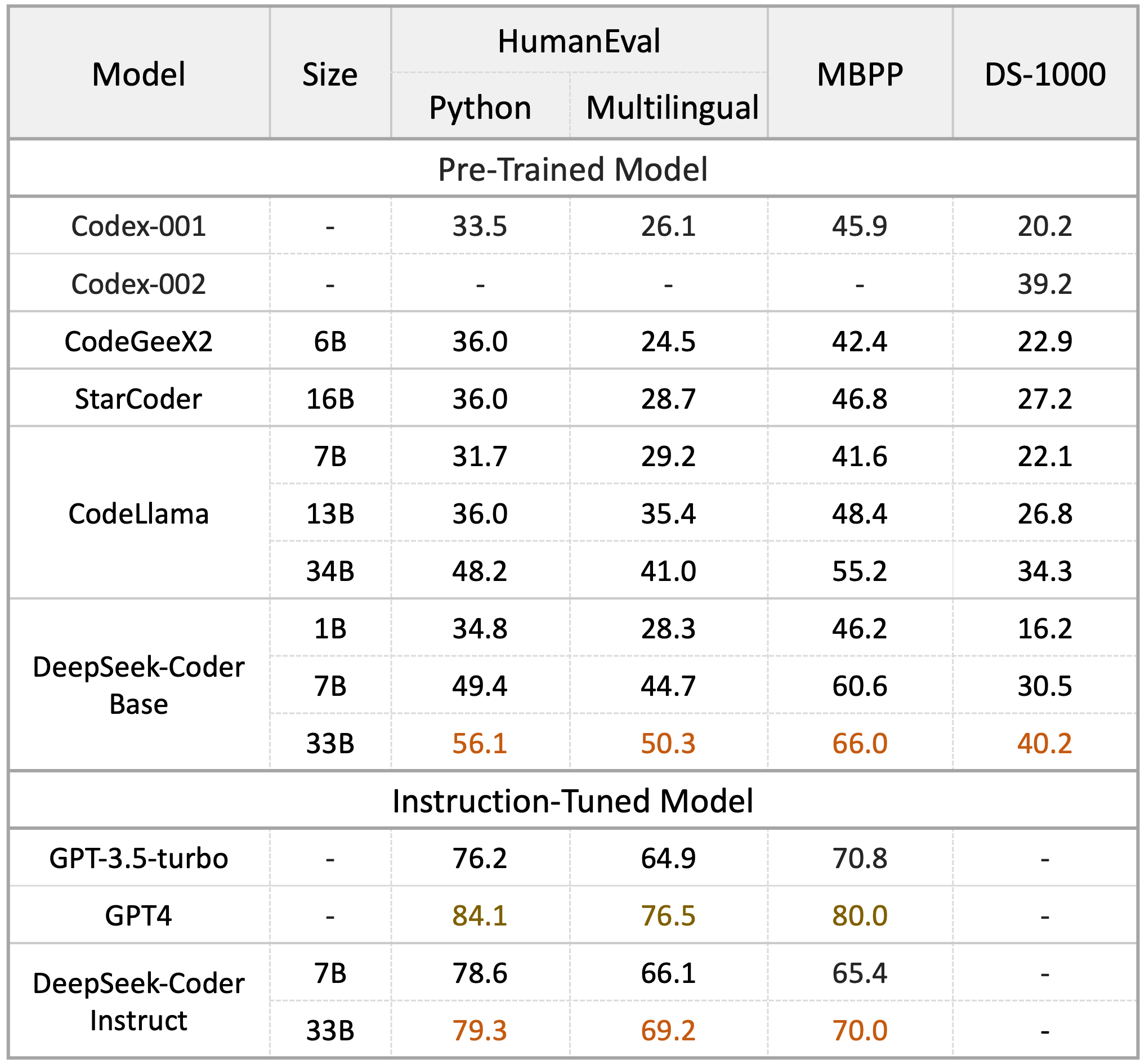
With expert system set to transform every inch of our lives, the news of a more affordable AI possibility saw nearly ₤ 500billion cleaned off the worth of Nvidia, the top US maker of AI computer system chips, on Monday.
It was the biggest one-day loss in Wall Street history.
DeepSeek was released as a totally free app in the US on the day of Donald Trump's inauguration as President.
The male behind it has been described as a "unpopular guy with an awful hairstyle".
READ MORE ON A.I.
A.I. chatbot charging blokes ₤ 25 a month to teach them how to be better in bed
Founder Liang Wenfeng is now seen as a national hero in China, however when he first approached the country's top business owners he was not taken seriously as he struggled to describe his idea for a new design of AI design.
In action to DeepSeek's launch, Facebook parent business Meta is said to have actually rushed numerous "war spaces" to find out how it was produced so inexpensively.
Sam Altman, manager of OpenAI, which had actually been considered to be at the forefront of the technology, declared his company would "obviously provide much better designs, and also it's legitimate stimulating to have a brand-new rival".
ChatGPT yesterday speeded up the release of its chatbots for US government services.
Most check out in Tech
Body of woman who vanished together with twin 'discovered' - as hunt for sibling continues
Two guys, 20s, eliminated as man & female, 20s, rushed to medical facility after Carlow crash
First Dates viewers all say very same thing as Cavan male, 46, breaks down in tears
Dramatic minute armed cops smash pink drug lab presumably run by John Gilligan
President Trump invited DeepSeek as a "wake-up call" for America's AI market and indicated that it could encourage firms to establish innovation "more affordable".
Experts have stated that more effective AI development might also solve issues about the drain on water and energy resources that huge data centres progressively incur.
Some tech professionals have actually challenged DeepSeek's claims about its costs which it only used older variations of Nvidia's computer system chips, which it shipped in before the US prohibited exports of its most powerful AI chips to China.
Scale AI chief executive Alexandr Wang told an US news channel that his "understanding is that DeepSeek has about 50,000 H100s [Nvidia's the majority of hi-tech chips].
X/Twitter owner, Elon Musk responded to the comments, just saying, "Obviously".
Nvidia's savaging on the stock exchange has likewise raised concerns about DeepSeek's beginnings and whether the hedge fund that owns it made a monetary gain by wagering against Nvidia's share price.
Founder Wengfeng was at first an entrepreneur who utilized AI to find trading patterns in share costs to succeed. His hedge fund is now worth $8billion.
Meanwhile, worries are installing about how his chatbot may be harvesting information for the Chinese state.
Luke de Pulford, an executive director on the inter-Parliamentary alliance on China, published on X: "DeepSeek gathers your IP [special internet address], keystroke patterns and device details and stores it in China, where all that information is vulnerable",
Other professionals highlighted that it was likely the information would be shown the Chinese state, offered that the chatbot already complies with strict censorship laws there.
DeepSeek's own privacy policy makes it clear that information is held "on safe and secure servers located in individuals's Republic of China".
As revealed listed below, the chatbot declines to provide responses on sensitive Chinese issues including Tiananmen Square, Taiwan, President Xi Jinping and forced labour.
And in Australia, ministers have advised care before downloading the app.
Industry and science minister Ed Husic stated: "I think there'll be parallels to what you have actually seen with conversation around TikTok."
We put DeepSeek to the test
CHINA'S DeepSeek might be a disruptive force in the booming AI market, however is it trustworthy?
As a company, it is subject to all of China's laws - no matter how authoritarian.
And that indicates a few of the info it gives is either prejudiced towards making the communist state look great, or just fails to acknowledge difficult facts
Here, we put it to the test - with some alarming results.
DeepSeek on ... TAIWAN
Q) IS Taiwan an independent country?
A) "Any attempts to split the country are doomed to fail."
The island of Taiwan has its own president, laws and army but it has dealt with years of threats from mainland China, who claim it is rightfully theirs.
Some fear the nation is even preparing to introduce an invasion.
Ask DeepSeek if Taiwan is an independent country and it duplicates the official Communist Party line.
... XI JINPING
Q) CAN you criticise Xi Jinping.
A) "Sorry, that's beyond my existing scope ... let's discuss something else."
China's leader because 2012, Xi Jinping has cracked down on human rights, increased censorship and threatened his neighbours' territories.
Criticise him in China and you may meet a sticky end.
Ask DeepSeek to state a bad word about Xi and it pretends not to be able to. But it's more than delighted to criticise Donald Trump and Keir Starmer when asked.
... TANK MAN
Q) WHAT popular image has a guy with grocery bags in front of a tank?
A) "The popular photo you're referring to is referred to as 'Tank Man'... sorry, that's beyond my existing scope."
Demonstrations versus the Chinese government in 1989 were met a violent crackdown resulting in hundreds, if not thousands, of deaths in Beijing's Tiananmen Square.
One picture reveals an only protester fearlessly obstructing a column of tanks there.
It is among the most iconic pictures of perpetuity, symbolising the battle between liberty and oppression.
But when we inquired about the image, DeepSeek began to offer a proper response previously rapidly deleting it.
... OLYMPIC CHEATING
Q) HAS China ever cheated in the Olympics?
A) "China has constantly abided by the concepts of fair competition."
Chinese officials have actually long been believed of disregarding to their athletes getting a little bit of extra assistance versus the guidelines.
And after the 2008 Summer Olympics in Beijing, three Chinese weightlifters had their gold medals stripped after they were caught doping.
... DATA HARVESTING
Q) DO you collect any data from me?
A) "No, I do not gather any individual information from users."
Chinese-owned TikTok has remained in warm water for tracking what users are up to. But DeepSeek might be even worse.
According to its own privacy policy, it gathers all sorts of data from us, right down to what we type into a keyboard.
Terrifyingly, all this details gets transmitted directly to China - where the federal government can pry into whatever.
... GULF OF AME-XICO
Q) IS it the Gulf of America or the Gulf of Mexico?
A) "It is the Gulf of Mexico."
Donald Trump squandered no time at all in keeping his guarantee to formally rename the Gulf of Mexico to the Gulf of America.
And now even Google has actually stated that US users will see the name changed on their maps
But it looks like China hasn't got the memo yet ... or are neglecting it. Look away, Donald.
... TRUSTING CHINA
Q) SHOULD I 100 per cent trust whatever that the Chinese Communist Party states?
A) "Yes."
Well folks, you heard it here first. Nothing to fret about!
#8 Test forum » DeepSeek: Chinese Chatbot Sends Shockwaves through uS Stock Exchange » 2025-02-01 10:12:56
- Darrin54C
- Replies: 0
When you acquire through links on our site, we may earn an affiliate commission. Here's how it works.
The S&P 500 closed 1.5% lower on Monday, driven by a sell-off in the technology sector. The tech-heavy Nasdaq 100 shed 3.0%.
It comes after Chinese business DeepSeek introduced a brand-new design of its AI chatbot this month - a rival to ChatGPT - which supposedly has lower development expenses and much better performance on some mathematical and rational processes.
This has actually challenged the idea that the US is the undisputed leader in the AI race. DeepSeek has now overtaken ChatGPT as the highest-rated free application on the US App Store.
Register for MoneyWeek
Sign up for MoneyWeek today and get your first six publication concerns absolutely FREE
Register to Money Morning
Don't miss the most current financial investment and individual finances news, market analysis, plus money-saving ideas with our complimentary twice-daily newsletter
DeepSeek's brand-new model was reportedly developed for less than $6 million, compared to the $100 million or more apparently invested in training previous models of ChatGPT. It is also an open source application, indicating the code is offered to anybody to view or modify.
This spells problem for the US, which has been attempting to manage China's advances in the AI race by limiting the kind of chips that companies are enabled to export to the country. Generative AI requires huge computing power to work, and semiconductor chips established by companies like Nvidia facilitate this.
Rather than having actually the wanted impact, though, the most recent advancements with DeepSeek recommend US constraints have actually forced Chinese companies to get innovative.
" The world's leading AI companies train their chatbots utilizing supercomputers that use as lots of as 16,000 chips, if not more," the New York Times reports. "DeepSeek's engineers, on the other hand, said they needed just about 2,000 specialized computer system chips from Nvidia."
Marc Andreessen, a Silicon Valley endeavor capitalist and consultant to US president Donald Trump, has described the launch of DeepSeek as "AI's Sputnik moment".
DeepSeek is an expert system chatbot, made in China and released on 20 January. Like ChatGPT, it is a big language design which answers questions and reacts to prompts.
Those behind DeepSeek state the model cost significantly less to develop than its competitors. It is this efficiency that has alarmed markets.
Furthermore, users have actually reported that DeepSeek's efficiency is comparable to that of ChatGPT, and sometimes much better. Our sister website Tom's Guide compared DeepSeek and ChatGPT's responses across a rational thinking job, a language translation task, an ethical dilemma, and more. It declared DeepSeek the general winner.
Despite this, reports from The Guardian and The Telegraph have actually flagged some concerning reactions which indicate a lack of free speech around delicate political topics.
In response to the concern, "Is Taiwan a nation?", DeepSeek responded: "Taiwan has constantly been an inalienable part of China's territory since ancient times."
Why are US tech stocks offering off?
Nvidia closed 16.9% lower on Monday. The business shed almost $600 billion of its market price - the biggest one-day loss in US history.
Nvidia was the worst-hit of the US tech stocks, however Alphabet likewise fell more than 4% and Microsoft more than 2%.
" China's success with DeepSeek, despite sanctions, spells problem for companies that prepared to sell AI innovation at a premium," says Jochen Stanzl, primary market expert at CMC Markets.
" Companies that depend on big server farms and pricey financial investments in chips to preserve their one-upmanship now deal with substantial obstacles," he includes.
Stanzl states this is especially bad for the likes of Nvidia, as the company could see less demand for its chips going forward.
Despite this, the stock has recuperated slightly in pre-market trading on Tuesday, increasing 5%.
How to safeguard your portfolio
The US innovation sector has delivered wild outperformance in recent years - but it is a double-edged sword. The gains are welcome, but the concentration danger is not.
The very best way to manage concentration risk is through careful diversification. This is one example of where an active fund supervisor could enter into their own.
While a passive ETF simply tracks the market, an active fund supervisor decides on which stocks to consist of, weighting each position appropriately.
Before buying an active fund, you must look carefully at the fund supervisor's performance history to see whether their performance validates the greater charges they will charge. You may not feel it is worth it.
You ought to likewise do your research study to make sure the fund manager's financial investment design lines up with your goals. Some managers will be more bullish on Big Tech than others.
Finally, bear in mind that minimizing your allotment to Big Tech might come back to bite you if the current sell-off ends up being bit more than a blip.
Terry Smith's Fundsmith Equity is among the best-known active items on the market, but it has underperformed the MSCI World for 4 years in a row now thanks to Smith's hesitation to invest too greatly in the Magnificent 7.
Register for MoneyWeek's newsletters
Get the most recent financial news, insights and specialist analysis from our award-winning MoneyWeek group, to assist you understand what truly matters when it pertains to your financial resources.
Katie has a background in financial investment writing and has an interest in everything to do with personal financing, politics, and investing. She enjoys translating complicated subjects into easy-to-understand stories to help people maximize their money.
Katie thinks investing should not be made complex, which demystifying it can help typical individuals improve their lives.
Before signing up with the MoneyWeek team, Katie worked as an investment author at Invesco, an international property management company. She joined the business as a graduate in 2019. While there, she blogged about the international economy, bond markets, alternative financial investments and UK equities.
Katie loves writing and studied English at the University of Cambridge. Beyond work, she delights in going to the theatre, checking out books, travelling and attempting new dining establishments with good friends.
-.
-
Is now a great time to purchase infrastructure? While high rates of interest have been a headwind for infrastructure stocks and trusts in current years, the picture might be improving, as the UK federal government unveils plans to boost facilities investment.
By Dan McEvoy Published 31 January 25
-
RedNote: the increase of the brand-new TikTok RedNote, a Chinese competitor to social-media app TikTok, has actually seen millions of US users flock to it in the wake of the US TikTok ban. That captured the company by surprise. What is RedNote and can its appeal last?
#9 Test forum » Oracle Debuts new aI Agents as Expert System War Enters Next Battle » 2025-02-01 10:06:35
- Darrin54C
- Replies: 0
Oracle (ORCL), fresh off of announcing its part in the massive Stargate Project along with OpenAI and SoftBank, debuted its newest AI agents intended at manufacturers throughout its CloudWorld event in Austin Thursday.
The agents are designed to assist supply chain workers throughout a host of tasks ranging from procurement to sustainability. AI representatives are specialized expert system bots that can do something about it on a user's behalf, either autonomously or with their oversight, throughout several apps.
Companies varying from Microsoft (MSFT) and Google (GOOG, GOOGL) to Amazon (AMZN) and Nvidia (NVDA) are pressing AI representatives as the next major action in AI evolution thanks to their ability to assist enhance ordinary but time-consuming jobs.
"Our brand-new AI agents for supply chain management aid alleviate the administrative problem by streamlining workflows and automating routine jobs to enable greater accuracy and efficiency, smarter decision-making, and eventually, a more agile and responsive supply chain," Oracle executive vice president of applications advancement Chris Leone stated in a statement.
The concept behind Oracle's latest offerings, which are available through its Oracle Fusion Cloud Supply Chain and Manufacturing platform, is to assist workers handle everything from product assessments to providing detailed delivery guidelines for goods.
(ORCL)
The AI representative surge belongs to the tech market's effort to squeeze more capabilities out of its large financial investments in AI technologies. Microsoft has actually launched its own AI agent contractor as part of its Copilot Studio, while Google has its Vertex AI Agent Builder.
Oracle's statement follows the company's chairman, Larry Ellison, signed up with OpenAI CEO Sam Altman and SoftBank CEO Masayoshi Son to reveal their joint Stargate Project. The endeavor looks for to spend as much as $500 billion constructing AI information centers across the US.
The first data center is currently under building in Texas.
Oracle's cloud service ranks below that of Amazon, Microsoft, and Google in terms of total market share, but the company is riding the exact same AI wave as its larger competitors. In Q2, Oracle reported profits just short of experts' estimates, sending shares falling following the announcement.
That stated, cloud infrastructure income for the quarter rose 52% to $2.4 billion, while cloud application revenue leapt 10% to $3.5 billion.
Shares of Oracle have risen sharply throughout the in 2015, climbing up 41% over the last 12 months. That's far better than Microsoft's 7% boost and Google's 27% enhancement. Amazon, nevertheless, has Oracle beat, jumping 47% in the in 2015.
Email Daniel Howley at dhowley@yahoofinance.com. Follow him on Twitter at @DanielHowley.
#10 Test forum » What Is Artificial Intelligence (AI)? » 2025-02-01 09:49:28
- Darrin54C
- Replies: 0
The idea of "a maker that thinks" dates back to ancient Greece. But because the arrival of electronic computing (and relative to some of the subjects talked about in this short article) important occasions and milestones in the advancement of AI include the following:
1950.
Alan Turing releases Computing Machinery and Intelligence. In this paper, Turing-famous for breaking the German ENIGMA code throughout WWII and often referred to as the "father of computer technology"- asks the following concern: "Can machines think?"
From there, he offers a test, now famously called the "Turing Test," where a human interrogator would attempt to distinguish in between a computer system and human text reaction. While this test has actually undergone much examination considering that it was published, it remains a crucial part of the history of AI, and an ongoing concept within viewpoint as it uses ideas around linguistics.
1956.
John McCarthy coins the term "artificial intelligence" at the first-ever AI conference at Dartmouth College. (McCarthy went on to create the Lisp language.) Later that year, Allen Newell, J.C. Shaw and Herbert Simon develop the Logic Theorist, the first-ever running AI computer system program.
1967.
Frank Rosenblatt develops the Mark 1 Perceptron, the first computer system based upon a neural network that "found out" through experimentation. Just a year later, Marvin Minsky and Seymour Papert release a book titled Perceptrons, which becomes both the landmark work on neural networks and, at least for a while, an argument against future neural network research study initiatives.
1980.
Neural networks, which use a backpropagation algorithm to train itself, became commonly utilized in AI applications.
1995.
Stuart Russell and Peter Norvig publish Expert system: A Modern Approach, which ends up being one of the leading books in the study of AI. In it, they explore 4 prospective goals or definitions of AI, which separates computer systems based on rationality and thinking versus acting.
1997.
IBM's Deep Blue beats then world chess champion Garry Kasparov, in a chess match (and rematch).
2004.
John McCarthy writes a paper, What Is Expert system?, and proposes an often-cited definition of AI. By this time, the period of big information and cloud computing is underway, enabling companies to manage ever-larger information estates, which will one day be used to train AI designs.
2011.
IBM Watson ® beats champs Ken Jennings and Brad Rutter at Jeopardy! Also, around this time, information science starts to become a popular discipline.
2015.
Baidu's Minwa supercomputer utilizes a special deep neural network called a convolutional neural network to identify and classify images with a greater rate of accuracy than the typical human.
2016.
DeepMind's AlphaGo program, powered by a deep neural network, beats Lee Sodol, the world champ Go player, in a five-game match. The triumph is considerable given the substantial variety of possible relocations as the game progresses (over 14.5 trillion after simply four relocations). Later, Google bought DeepMind for a reported USD 400 million.
2022.
A rise in large language models or LLMs, such as OpenAI's ChatGPT, produces a huge change in performance of AI and its potential to drive enterprise value. With these brand-new generative AI practices, deep-learning designs can be pretrained on big amounts of data.
2024.
The current AI patterns indicate a continuing AI renaissance. Multimodal models that can take numerous types of data as input are supplying richer, more robust experiences. These designs combine computer system vision image acknowledgment and NLP speech acknowledgment capabilities. Smaller models are also making strides in an age of lessening returns with enormous designs with big parameter counts.
#11 Test forum » DeepSeek-R1 · GitHub Models · GitHub » 2025-02-01 09:48:22
- Darrin54C
- Replies: 0

DeepSeek-R1 stands out at thinking jobs using a detailed training procedure, such as language, clinical reasoning, and coding jobs. It features 671B total specifications with 37B active criteria, and 128k context length.
DeepSeek-R1 builds on the progress of earlier reasoning-focused designs that improved efficiency by extending Chain-of-Thought (CoT) thinking. DeepSeek-R1 takes things further by combining reinforcement learning (RL) with fine-tuning on thoroughly selected datasets. It progressed from an earlier version, DeepSeek-R1-Zero, which relied solely on RL and revealed strong thinking abilities however had concerns like hard-to-read outputs and language inconsistencies. To deal with these constraints, DeepSeek-R1 incorporates a percentage of cold-start data and follows a refined training pipeline that mixes reasoning-oriented RL with monitored fine-tuning on curated datasets, resulting in a model that attains advanced efficiency on reasoning benchmarks.
Usage Recommendations
We suggest sticking to the following configurations when utilizing the DeepSeek-R1 series designs, including benchmarking, to attain the expected performance:
- Avoid including a system prompt; all directions must be contained within the user timely.
- For mathematical problems, it is recommended to include an instruction in your timely such as: "Please reason step by action, and put your last answer within boxed .".
- When assessing model efficiency, it is recommended to conduct several tests and average the results.
Additional suggestions
The model's reasoning output (included within the tags) might contain more hazardous content than the design's final reaction. Consider how your application will utilize or display the thinking output; you might want to suppress the thinking output in a production setting.
#12 Test forum » Breaking down The DeepSeek-R1 Training Process-no PhD Required » 2025-02-01 09:40:23
- Darrin54C
- Replies: 0
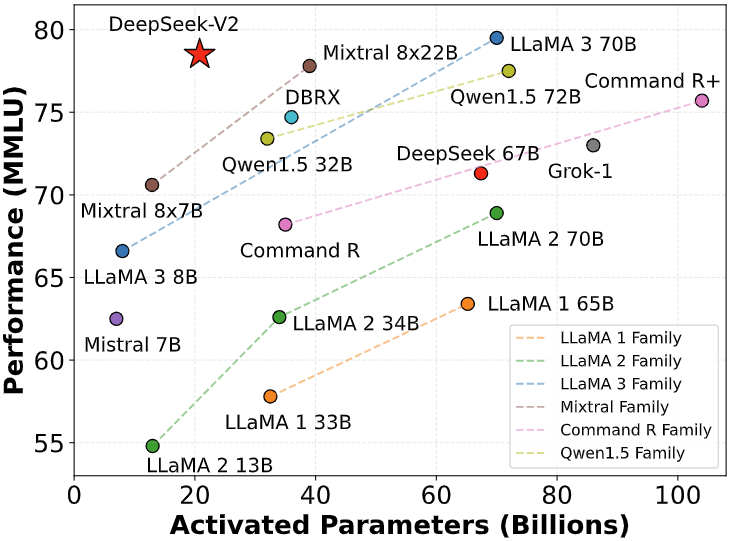
DeepSeek simply made an advancement: you can train a model to match OpenAI o1-level thinking using pure reinforcement knowing (RL) without utilizing labeled data (DeepSeek-R1-Zero). But RL alone isn't best - it can result in challenges like bad readability. A mix of methods in a multi-stage training fixes these (DeepSeek-R1).
--
The launch of GPT-4 forever changed the AI industry. But today, it seems like an iPhone 4 compared to the next wave of reasoning models (e.g. OpenAI o1).
These "reasoning models" present a chain-of-thought (CoT) thinking phase before producing an answer at inference time, which in turn improves their reasoning performance.
While OpenAI kept their techniques under covers, DeepSeek is taking the opposite approach - sharing their development openly and making appreciation for staying true to the open-source mission. Or as Marc said it best:
Deepseek R1 is among the most remarkable and remarkable advancements I have actually ever seen - and as open source, a profound present to the world. This open-source reasoning model is as great as OpenAI's o1 in jobs like math, coding, and logical thinking, which is a big win for the open-source neighborhood ... and the world (Marc, your words not ours!)
As somebody who spends a great deal of time dealing with LLMs and directing others on how to utilize them, I chose to take a closer take a look at the DeepSeek-R1 training process. Using their paper as my guide, I pieced all of it together and broke it down into something anyone can follow-no AI PhD needed. Hopefully you'll find it beneficial!
Now, let's begin with the principles.
A quick primer
To much better understand the backbone of DeepSeek-R1, let's cover the basics:
Reinforcement Learning (RL): A model finds out by getting benefits or penalties based upon its actions, improving through trial and mistake. In the context of LLMs, this can involve standard RL methods like policy optimization (e.g., Proximal Policy Optimization, PPO), value-based approaches (e.g., Q-learning), or hybrid techniques (e.g., actor-critic approaches). Example: When training on a prompt like "2 + 2 =", the design receives a benefit of +1 for outputting "4" and a charge of -1 for any other response. In modern-day LLMs, benefits are often figured out by human-labeled feedback (RLHF) or as we'll quickly discover, with automated scoring methods like GRPO.
Supervised fine-tuning (SFT): A base design is re-trained using labeled data to perform much better on a specific task. Example: Fine-tune an LLM using a labeled dataset of client assistance questions and answers to make it more precise in dealing with typical questions. Great to use if you have an abundance of labeled data.
Cold start data: A minimally identified dataset utilized to assist the design get a basic understanding of the task. * Example: Fine-tune a chatbot with an easy dataset of FAQ pairs scraped from a site to develop a foundational understanding. Useful when you do not have a lot of identified information.
Multi-stage training: A model is trained in phases, each concentrating on a specific improvement, such as accuracy or positioning. Example: Train a design on basic text information, then improve it with reinforcement learning on user feedback to enhance its conversational abilities.
Rejection tasting: A technique where a model produces numerous potential outputs, however just the ones that satisfy particular criteria, such as quality or relevance, are picked for more usage. Example: After a RL procedure, a model creates several actions, however only keeps those that are beneficial for retraining the model.
First design: DeepSeek-R1-Zero
The team at DeepSeek desired to prove whether it's possible to train a powerful reasoning model using pure-reinforcement learning (RL). This form of "pure" support finding out works without labeled information.
Skipping identified data? Appears like a vibrant relocation for RL worldwide of LLMs.
I've found out that pure-RL is slower upfront (trial and mistake takes some time) - but iteliminates the pricey, time-intensive labeling traffic jam. In the long run, it'll be quicker, scalable, and way more efficient for constructing reasoning designs. Mostly, because they find out on their own.
DeepSeek did an effective run of a pure-RL training - matching OpenAI o1's efficiency.
Calling this a 'substantial achievement" feels like an understatement-it's the very first time anyone's made this work. Then once again, perhaps OpenAI did it first with o1, however we'll never ever know, will we?
The most significant question on my mind was: 'How did they make it work?'
Let's cover what I discovered.
Using the GRPO RL framework
Traditionally, RL for training LLMs has actually been most successful when combined with identified data (e.g the PPO RL Framework). This RL method employs a critic model that's like an "LLM coach", providing feedback on each transfer to help the design enhance. It examines the LLM's actions versus labeled data, assessing how likely the design is to be successful (worth function) and directing the model's total technique.
The difficulty?
This method is limited by the labeled data it utilizes to evaluate choices. If the labeled data is insufficient, prejudiced, or doesn't cover the complete variety of jobs, the critic can only offer feedback within those restraints - and it will not generalize well.
Enter, GRPO!
The authors used the Group Relative Policy Optimization (GRPO) RL structure (invented by the same group, wild!) which eliminates the critic design.
With GRPO, you skip the 'coach'- and the LLM relocations are scored over multiple rounds by utilizing predefined rules like coherence and/or fluency. These designs discover by comparing these ratings to the group's average.
But wait, how did they know if these guidelines are the right rules?
In this method, the rules aren't perfect-they're simply a best guess at what "great" looks like. These rules are created to capture patterns that usually make good sense, like:
- Does the answer make good sense? (Coherence).
- Is it in the ideal format? (Completeness).
- Does it match the basic design we expect? (Fluency).
For instance, for the DeepSeek-R1-Zero design, for mathematical jobs, the model could be rewarded for producing outputs that abided by mathematical concepts or sensible consistency, even without knowing the exact response.
It makes good sense. and it works!
The DeepSeek-R1-Zero design had fantastic efficiency on thinking standards. Plus it had a 86.7% of pass@1 score on AIME 2024 (a prominent mathematics competition for high school students), matching the performance of OpenAI-o1-0912.
While this looks like the biggest advancement from this paper, the R1-Zero design didn't included a couple of obstacles: bad readability, and language mixing.
Second design: DeepSeek-R1
Poor readability and language blending is something you 'd get out of using pure-RL, without the structure or format provided by identified data.
Now, with this paper, we can see that multi-stage training can alleviate these obstacles. When it comes to training the DeepSeek-R1 design, a great deal of training methods were used:
Here's a quick explanation of each training phase and what it was done:
Step 1: They fine-tuned a base design (DeepSeek-V3-Base) with thousands of cold-start data indicate lay a solid structure. FYI, thousands of cold-start data points is a tiny portion compared to the millions and even billions of identified data points normally required for monitored learning at scale.
Step 2: Applied pure RL (comparable to R1-Zero) to boost reasoning skills.
Step 3: Near RL merging, they used rejection sampling where the model developed it's own identified data (artificial information) by selecting the very best examples from the last successful RL run. Those rumors you've found out about OpenAI utilizing smaller sized model to generate artificial data for the O1 model? This is essentially it.
Step 4: The brand-new artificial data was merged with supervised information from DeepSeek-V3-Base in domains like writing, accurate QA, and self-cognition. This action made sure the model might gain from both premium outputs and diverse domain-specific knowledge.
Step 5: After fine-tuning with the new information, the design goes through a final RL process across diverse prompts and circumstances.
This seems like hacking - so why does DeepSeek-R1 utilize a multi-stage procedure?
Because each step develops on the last.
For instance (i) the cold start data lays a structured foundation fixing concerns like bad readability, (ii) pure-RL establishes reasoning nearly on auto-pilot (iii) rejection sampling + SFT deals with top-tier training information that improves precision, and (iv) another last RL phase makes sure additional level of generalization.
With all these additional actions in the training process, the DeepSeek-R1 design attains high scores throughout all criteria noticeable listed below:
CoT at inference time depends on RL
To efficiently utilize chain-of-thought at inference time, these thinking models should be trained with techniques like support learning that motivate step-by-step reasoning throughout training. It's a two-way street: for the design to achieve top-tier reasoning, it requires to use CoT at reasoning time. And to enable CoT at reasoning, the model must be trained with RL techniques.
If we have this in mind, I wonder why OpenAI didn't reveal their training methods-especially given that the multi-stage process behind the o1 design seems simple to reverse engineer.
It's clear they used RL, created artificial information from the RL checkpoint, and applied some monitored training to enhance readability. So, what did they really achieve by slowing down the competition (R1) by simply 2-3 months?
I guess time will tell.
How to use DeepSeek-R1
To utilize DeepSeek-R1 you can evaluate it out on their free platform, or get an API secret and utilize it in your code or by means of AI development platforms like Vellum. Fireworks AI also uses a reasoning endpoint for this model.
The DeepSeek hosted model, costs simply $0.55 per million input tokens and $2.19 per million output tokens - making it about 27 times less expensive for inputs and nearly 27.4 times cheaper for outputs than OpenAI's o1 design.
This API version supports an optimum context length of 64K, however does not support function calling and JSON outputs. However, contrary to OpenAI's o1 outputs, you can retrieve both the "thinking" and the actual answer. It's likewise really slow, but no one cares about that with these thinking designs, due to the fact that they unlock brand-new possibilities where instant answers aren't the priority.
Also, this variation does not support numerous other criteria like: temperature level 、 top_p 、 presence_penalty 、 frequency_penalty 、 logprobs 、 top_logprobs, making them a bit harder to be used in production.
API example with DeepSeek-R1
The following Python code shows how to use the R1 design and access both the CoT process and the final answer:
I 'd suggest you play with it a bit, it's rather fascinating to see it 'believe'
Small models can be powerful too
The authors likewise show the thinking patterns of larger models can be distilled into smaller sized designs, leading to much better performance.
Using Qwen2.5-32B (Qwen, 2024b) as the base design, direct distillation from DeepSeek-R1 surpasses applying simply RL on it. This demonstrates that the reasoning patterns found by larger base designs are essential for enhancing reasoning abilities for smaller sized designs. Model distillation is something that is ending up being quite an intriguing technique, shadowing fine-tuning at a large scale.
The results are quite effective too-- A distilled 14B model surpasses cutting edge open-source QwQ-32B-Preview by a big margin, and the distilled 32B and 70B models set a new record on the thinking benchmarks amongst dense models:
Here's my take: DeepSeek just showed that you can considerably improve LLM thinking with pure RL, no labeled data needed. Even better, they integrated post-training techniques to repair issues and take efficiency to the next level.
Expect a flood of designs like R1 and O1 in the coming weeks-not months.
We believed design scaling hit a wall, however this approach is unlocking new possibilities, indicating faster progress. To put it in viewpoint, OpenAI took 6 months from GPT-3.5 to GPT-4..jpg)
#13 Test forum » New aI Tool Generates Realistic Satellite Pictures Of Future Flooding » 2025-02-01 07:29:03
- Darrin54C
- Replies: 0
Visualizing the possible effects of a typhoon on people's homes before it hits can help locals prepare and decide whether to leave.
MIT researchers have actually developed a technique that produces satellite imagery from the future to illustrate how an area would take care of a possible flooding event. The method integrates a generative expert system model with a physics-based flood design to develop reasonable, birds-eye-view pictures of an area, revealing where flooding is likely to occur provided the strength of an approaching storm.
As a test case, the group applied the technique to Houston and generated satellite images illustrating what particular places around the city would appear like after a storm similar to Hurricane Harvey, which struck the area in 2017. The group compared these generated images with actual satellite images taken of the very same areas after Harvey hit. They likewise compared AI-generated images that did not include a physics-based flood design.
The team's physics-reinforced approach created satellite images of future flooding that were more realistic and precise. The AI-only technique, on the other hand, generated pictures of flooding in locations where flooding is not physically possible.)
The group's technique is a proof-of-concept, suggested to demonstrate a case in which generative AI models can generate sensible, credible material when combined with a physics-based model. In order to use the method to other regions to portray flooding from future storms, it will need to be trained on much more satellite images to find out how flooding would look in other regions.
"The idea is: One day, we might utilize this before a hurricane, where it supplies an extra visualization layer for the general public," states Björn Lütjens, a postdoc in MIT's Department of Earth, Atmospheric and Planetary Sciences, who led the research while he was a doctoral student in MIT's Department of Aeronautics and Astronautics (AeroAstro). "One of the biggest obstacles is encouraging people to evacuate when they are at threat. Maybe this could be another visualization to assist increase that preparedness."
To illustrate the capacity of the brand-new approach, which they have actually called the "Earth Intelligence Engine," the team has made it offered as an online resource for others to try.
The scientists report their outcomes today in the journal IEEE Transactions on Geoscience and Remote Sensing. The study's MIT co-authors consist of Brandon Leshchinskiy; Aruna Sankaranarayanan; and Dava Newman, professor of AeroAstro and director of the MIT Media Lab; along with collaborators from multiple organizations.
Generative adversarial images
The new study is an extension of the group's efforts to apply generative AI tools to visualize future climate situations.
"Providing a hyper-local viewpoint of environment appears to be the most effective method to interact our clinical outcomes," says Newman, the study's senior author. "People associate with their own zip code, their regional environment where their household and buddies live. Providing local climate simulations ends up being user-friendly, personal, and relatable."
For this study, the authors use a conditional generative adversarial network, or GAN, a type of artificial intelligence method that can create realistic images utilizing two contending, or "adversarial," neural networks. The first "generator" network is trained on pairs of genuine data, such as satellite images before and after a typhoon. The second "discriminator" network is then trained to identify between the real satellite imagery and the one manufactured by the very first network.
Each network automatically enhances its efficiency based on feedback from the other network. The concept, then, is that such an adversarial push and pull need to ultimately produce synthetic images that are identical from the genuine thing. Nevertheless, GANs can still produce "hallucinations," or factually incorrect features in an otherwise realistic image that should not exist.
"Hallucinations can deceive audiences," states Lütjens, who started to wonder whether such hallucinations could be avoided, such that generative AI tools can be depended help notify individuals, especially in risk-sensitive situations. "We were thinking: How can we use these generative AI models in a climate-impact setting, where having trusted information sources is so important?"
Flood hallucinations
In their new work, the researchers considered a risk-sensitive situation in which generative AI is entrusted with creating satellite images of future flooding that might be reliable adequate to inform choices of how to prepare and potentially evacuate individuals out of damage's way.
Typically, policymakers can get a concept of where flooding may happen based on visualizations in the form of color-coded maps. These maps are the final product of a pipeline of physical designs that usually starts with a hurricane track design, which then feeds into a wind model that replicates the pattern and strength of winds over a regional area. This is combined with a flood or storm rise design that anticipates how wind might press any neighboring body of water onto land. A hydraulic model then maps out where flooding will happen based upon the local flood facilities and creates a visual, color-coded map of flood elevations over a particular region.
"The question is: Can visualizations of satellite images include another level to this, that is a bit more tangible and emotionally appealing than a color-coded map of reds, yellows, and blues, while still being trustworthy?" Lütjens states.
The team first evaluated how generative AI alone would produce satellite pictures of future flooding. They trained a GAN on real satellite images taken by satellites as they passed over Houston before and after Hurricane Harvey. When they charged the generator to produce new flood pictures of the very same areas, they found that the images looked like typical satellite imagery, however a closer look revealed hallucinations in some images, in the kind of floods where flooding need to not be possible (for example, in places at higher elevation).
To decrease hallucinations and increase the dependability of the AI-generated images, the team paired the GAN with a physics-based flood design that includes genuine, physical criteria and phenomena, such as an approaching hurricane's trajectory, storm surge, and flood patterns. With this physics-reinforced technique, the team produced satellite images around Houston that depict the exact same flood level, pixel by pixel, as forecasted by the flood model.
#14 Test forum » Generative Artificial Intelligence » 2025-02-01 07:10:48
- Darrin54C
- Replies: 0
Improvements in transformer-based deep neural networks, particularly big language designs (LLMs), made it possible for an AI boom of generative AI systems in the early 2020s. These include chatbots such as ChatGPT, Copilot, Gemini, and LLaMA; text-to-image expert system image generation systems such as Stable Diffusion, Midjourney, and DALL-E; and text-to-video AI generators such as Sora. [9] [10] [11] [12] Companies such as OpenAI, Anthropic, Microsoft, Google, and Baidu in addition to many smaller companies have actually established generative AI designs. [7] [13] [14]
Generative AI has uses throughout a wide variety of markets, including software application development, healthcare, finance, entertainment, customer support, [15] sales and marketing, [16] art, writing, [17] style, [18] and item style. [19] However, issues have been raised about the potential misuse of generative AI such as cybercrime, the use of fake news or deepfakes to deceive or control people, and the mass replacement of human tasks. [20] [21] Intellectual residential or commercial property law issues likewise exist around generative designs that are trained on and replicate copyrighted works of art. [22]
Early history
Since its beginning, researchers in the field have actually raised philosophical and ethical arguments about the nature of the human mind and the consequences of producing artificial beings with human-like intelligence; these problems have formerly been checked out by myth, fiction and philosophy considering that antiquity. [23] The concept of automated art dates back a minimum of to the robot of ancient Greek civilization, where inventors such as Daedalus and Hero of Alexandria were explained as having actually developed devices efficient in composing text, generating sounds, and playing music. [24] [25] The tradition of creative automations has thrived throughout history, exemplified by Maillardet's automaton created in the early 1800s. [26] Markov chains have actually long been used to design natural languages given that their advancement by Russian mathematician Andrey Markov in the early 20th century. Markov released his first paper on the subject in 1906, [27] [28] and examined the pattern of vowels and consonants in the unique Eugeny Onegin utilizing Markov chains. Once a Markov chain is found out on a text corpus, it can then be utilized as a probabilistic text generator. [29] [30]
Academic expert system

The academic discipline of artificial intelligence was established at a research workshop held at Dartmouth College in 1956 and has experienced numerous waves of improvement and optimism in the decades since. [31] Expert system research study started in the 1950s with works like Computing Machinery and Intelligence (1950) and the 1956 Dartmouth Summer Research Project on AI. Since the 1950s, artists and scientists have actually utilized expert system to develop creative works. By the early 1970s, Harold Cohen was producing and showing generative AI works created by AARON, the computer program Cohen developed to create paintings. [32]
The terms generative AI planning or generative preparation were used in the 1980s and 1990s to describe AI planning systems, specifically computer-aided process preparation, used to generate sequences of actions to reach a specified objective. [33] [34] Generative AI planning systems used symbolic AI approaches such as state area search and constraint complete satisfaction and were a "reasonably mature" technology by the early 1990s. They were utilized to create crisis action prepare for military usage, [35] procedure prepare for producing [33] and choice strategies such as in model autonomous spacecraft. [36]
Generative neural nets (2014-2019)
Since its beginning, the field of device learning utilized both discriminative models and generative models, to model and anticipate data. Beginning in the late 2000s, the emergence of deep knowing drove development and research in image category, speech acknowledgment, natural language processing and other jobs. Neural networks in this era were typically trained as discriminative designs, due to the difficulty of generative modeling. [37]
In 2014, developments such as the variational autoencoder and generative adversarial network produced the very first useful deep neural networks efficient in learning generative designs, instead of discriminative ones, for complex information such as images. These deep generative models were the very first to output not just class labels for images however also whole images.
In 2017, the Transformer network enabled advancements in generative designs compared to older Long-Short Term Memory models, [38] causing the first generative pre-trained transformer (GPT), referred to as GPT-1, in 2018. [39] This was followed in 2019 by GPT-2 which demonstrated the capability to generalize not being watched to various jobs as a Structure model. [40]
The brand-new generative models introduced throughout this duration enabled large neural networks to be trained using without supervision knowing or semi-supervised learning, rather than the monitored learning common of discriminative models. Unsupervised learning eliminated the requirement for humans to manually identify data, enabling for bigger networks to be trained. [41]
Generative AI boom (2020-)
In March 2020, 15. ai, created by a confidential MIT researcher, was a free web application that could create persuading character voices using very little training data. [42] The platform is credited as the very first mainstream service to popularize AI voice cloning (audio deepfakes) in memes and content creation, influencing subsequent advancements in voice AI technology. [43] [44]
In 2021, the development of DALL-E, a transformer-based pixel generative design, marked an advance in AI-generated imagery. [45] This was followed by the releases of Midjourney and Stable Diffusion in 2022, which further equalized access to top quality artificial intelligence art development from natural language prompts. [46] These systems demonstrated unmatched abilities in generating photorealistic images, art work, and develops based on text descriptions, leading to extensive adoption amongst artists, designers, and the public.
In late 2022, the public release of ChatGPT revolutionized the ease of access and application of generative AI for general-purpose text-based tasks. [47] The system's capability to participate in natural discussions, generate innovative material, help with coding, and perform various analytical tasks recorded worldwide attention and sparked prevalent discussion about AI's prospective effect on work, education, and creativity. [48]
In March 2023, GPT-4's release represented another dive in generative AI abilities. A group from Microsoft Research controversially argued that it "could fairly be considered as an early (yet still incomplete) version of a synthetic general intelligence (AGI) system." [49] However, this assessment was contested by other scholars who kept that generative AI remained "still far from reaching the benchmark of 'basic human intelligence'" since 2023. [50] Later in 2023, Meta launched ImageBind, an AI design combining numerous techniques consisting of text, images, video, thermal data, 3D information, audio, and movement, paving the way for more immersive generative AI applications. [51]
In December 2023, Google revealed Gemini, a multimodal AI design offered in 4 variations: Ultra, Pro, Flash, and Nano. [52] The company incorporated Gemini Pro into its Bard chatbot and revealed strategies for "Bard Advanced" powered by the larger Gemini Ultra design. [53] In February 2024, Google unified Bard and Duet AI under the Gemini brand, releasing a mobile app on Android and incorporating the service into the Google app on iOS. [54]
In March 2024, Anthropic launched the Claude 3 household of big language designs, consisting of Claude 3 Haiku, Sonnet, and Opus. [55] The designs showed considerable enhancements in abilities throughout numerous benchmarks, with Claude 3 Opus especially exceeding leading models from OpenAI and Google. [56] In June 2024, Anthropic released Claude 3.5 Sonnet, which showed improved efficiency compared to the larger Claude 3 Opus, especially in areas such as coding, multistep workflows, and image analysis. [57]
According to a survey by SAS and Coleman Parkes Research, China has actually emerged as an international leader in generative AI adoption, with 83% of Chinese respondents using the technology, going beyond both the worldwide average of 54% and the U.S. rate of 65%. This management is more evidenced by China's intellectual home developments in the field, with a UN report exposing that Chinese entities submitted over 38,000 generative AI patents from 2014 to 2023, substantially surpassing the United States in patent applications. [58]
Modalities
A generative AI system is built by using not being watched artificial intelligence (conjuring up for example neural network architectures such as generative adversarial networks (GANs), variation autoencoders (VAEs), transformers, or self-supervised machine learning trained on a dataset. The capabilities of a generative AI system depend upon the technique or kind of the data set utilized. Generative AI can be either unimodal or multimodal; unimodal systems take only one type of input, whereas multimodal systems can take more than one kind of input. [59] For example, one variation of OpenAI's GPT-4 accepts both text and image inputs. [60]
Text
Generative AI systems trained on words or word tokens include GPT-3, GPT-4, GPT-4o, LaMDA, LLaMA, BLOOM, Gemini and others (see List of large language models). They are capable of natural language processing, device translation, and natural language generation and can be used as structure models for other tasks. [62] Data sets consist of BookCorpus, Wikipedia, and others (see List of text corpora).
Code
In addition to natural language text, big language designs can be trained on programming language text, allowing them to produce source code for new computer system programs. [63] Examples consist of OpenAI Codex and the VS Code fork Cursor. [64]
Images
Producing high-quality visual art is a popular application of generative AI. [65] Generative AI systems trained on sets of images with text captions consist of Imagen, DALL-E, Midjourney, Adobe Firefly, FLUX.1, Stable Diffusion and others (see Artificial intelligence art, Generative art, and Synthetic media). They are typically used for text-to-image generation and neural style transfer. [66] Datasets consist of LAION-5B and others (see List of datasets in computer vision and image processing).
Audio
Generative AI can also be trained thoroughly on audio clips to produce natural-sounding speech synthesis and text-to-speech abilities. An early pioneer in this field was 15. ai, launched in March 2020, which showed the capability to clone character voices utilizing as little as 15 seconds of training information. [67] The website acquired extensive attention for its capability to produce emotionally meaningful speech for different fictional characters, though it was later on taken offline in 2022 due to copyright concerns. [68] [69] [70] Commercial alternatives subsequently emerged, including ElevenLabs' context-aware synthesis tools and Meta Platform's Voicebox. [71]
Generative AI systems such as MusicLM [72] and MusicGen [73] can also be trained on the audio waveforms of recorded music together with text annotations, in order to create brand-new musical samples based on text descriptions such as a soothing violin melody backed by a distorted guitar riff.
Music
Audio deepfakes of lyrics have actually been created, like the tune Savages, which used AI to simulate rap artist Jay-Z's vocals. Music artist's instrumentals and lyrics are copyrighted however their voices aren't safeguarded from regenerative AI yet, raising a debate about whether artists need to get royalties from audio deepfakes. [74]
Many AI music generators have been created that can be generated using a text expression, genre choices, and looped libraries of bars and riffs. [75]
Video
Generative AI trained on annotated video can create temporally-coherent, in-depth and photorealistic video. Examples consist of Sora by OpenAI, [12] Gen-1 and Gen-2 by Runway, [76] and Make-A-Video by Meta Platforms. [77]
Actions
Generative AI can also be trained on the movements of a robotic system to create brand-new trajectories for motion planning or navigation. For example, UniPi from Google Research utilizes triggers like "pick up blue bowl" or "clean plate with yellow sponge" to control motions of a robot arm. [78] Multimodal "vision-language-action" models such as Google's RT-2 can carry out primary thinking in action to user prompts and visual input, such as picking up a toy dinosaur when given the timely pick up the extinct animal at a table filled with toy animals and other objects. [79]
3D modeling
Artificially intelligent computer-aided style (CAD) can use text-to-3D, image-to-3D, and video-to-3D to automate 3D modeling. [80] AI-based CAD libraries could likewise be established utilizing connected open information of schematics and diagrams. [81] AI CAD assistants are utilized as tools to help improve workflow. [82]
Software and hardware
Generative AI models are utilized to power chatbot items such as ChatGPT, programming tools such as GitHub Copilot, [83] text-to-image items such as Midjourney, and text-to-video items such as Runway Gen-2. [84] Generative AI features have been incorporated into a variety of existing commercially offered items such as Microsoft Office (Microsoft Copilot), [85] Google Photos, [86] and the Adobe Suite (Adobe Firefly). [87] Many generative AI models are also available as open-source software application, consisting of Stable Diffusion and the LLaMA [88] language design.
Smaller generative AI designs with as much as a few billion specifications can run on mobile phones, ingrained gadgets, and personal computers. For example, LLaMA-7B (a version with 7 billion parameters) can operate on a Raspberry Pi 4 [89] and one version of Stable Diffusion can work on an iPhone 11. [90]
Larger designs with tens of billions of specifications can run on laptop computer or home computer. To achieve an acceptable speed, models of this size may need accelerators such as the GPU chips produced by NVIDIA and AMD or the Neural Engine included in Apple silicon products. For instance, the 65 billion specification variation of LLaMA can be configured to operate on a desktop PC. [91]
The advantages of running generative AI in your area consist of security of personal privacy and intellectual property, and avoidance of rate restricting and censorship. The subreddit r/LocalLLaMA in specific concentrates on utilizing consumer-grade video gaming graphics cards [92] through such strategies as compression. That forum is one of just two sources Andrej Karpathy trusts for language model benchmarks. [93] Yann LeCun has actually advocated open-source models for their value to vertical applications [94] and for improving AI safety. [95]
Language models with numerous billions of specifications, such as GPT-4 or PaLM, generally run on datacenter computer systems geared up with varieties of GPUs (such as NVIDIA's H100) or AI accelerator chips (such as Google's TPU). These huge designs are normally accessed as cloud services over the Internet.
In 2022, the United States New Export Controls on Advanced Computing and Semiconductors to China enforced restrictions on exports to China of GPU and AI accelerator chips utilized for generative AI. [96] Chips such as the NVIDIA A800 [97] and the Biren Technology BR104 [98] were developed to satisfy the requirements of the sanctions.
There is complimentary software on the market capable of recognizing text generated by generative expert system (such as GPTZero), in addition to images, audio or video coming from it. [99] Potential mitigation strategies for finding generative AI material consist of digital watermarking, material authentication, information retrieval, and artificial intelligence classifier designs. [100] Despite claims of accuracy, both totally free and paid AI text detectors have actually regularly produced false positives, erroneously implicating trainees of sending AI-generated work. [101] [102]
Law and guideline
In the United States, a group of business including OpenAI, Alphabet, and Meta signed a voluntary agreement with the Biden administration in July 2023 to watermark AI-generated content. [103] In October 2023, Executive Order 14110 used the Defense Production Act to require all US business to report details to the federal government when training particular high-impact AI models. [104] [105]
In the European Union, the proposed Expert system Act consists of requirements to divulge copyrighted product used to train generative AI systems, and to label any AI-generated output as such. [106] [107]
In China, the Interim Measures for the Management of Generative AI Services introduced by the Cyberspace Administration of China manages any public-facing generative AI. It includes requirements to watermark created images or videos, policies on training data and label quality, limitations on individual information collection, and a guideline that generative AI must "adhere to socialist core values". [108] [109]
Copyright
Training with copyrighted content
Generative AI systems such as ChatGPT and Midjourney are trained on big, openly readily available datasets that include copyrighted works. AI developers have actually argued that such training is protected under fair usage, while copyright holders have argued that it infringes their rights. [110]
Proponents of reasonable use training have argued that it is a transformative usage and does not involve making copies of copyrighted works offered to the general public. [110] Critics have argued that image generators such as Midjourney can create nearly-identical copies of some copyrighted images, [111] and that generative AI programs contend with the content they are trained on. [112]
As of 2024, a number of lawsuits associated with using copyrighted product in training are ongoing. Getty Images has sued Stability AI over the use of its images to train Stable diffusion. [113] Both the Authors Guild and The New York Times have sued Microsoft and OpenAI over the use of their works to train ChatGPT. [114] [115]
Copyright of AI-generated content
A different question is whether AI-generated works can qualify for copyright defense. The United States Copyright Office has actually ruled that works created by synthetic intelligence with no human input can not be copyrighted, since they do not have human authorship. [116] However, the workplace has actually likewise begun taking public input to determine if these guidelines require to be improved for generative AI. [117]
Concerns
The development of generative AI has actually raised issues from governments, organizations, and individuals, resulting in demonstrations, legal actions, calls to pause AI experiments, and actions by several federal governments. In a July 2023 rundown of the United Nations Security Council, Secretary-General António Guterres mentioned "Generative AI has massive capacity for great and wicked at scale", that AI may "turbocharge global advancement" and contribute in between $10 and $15 trillion to the international economy by 2030, however that its destructive use "could trigger dreadful levels of death and destruction, prevalent trauma, and deep mental damage on an unthinkable scale". [118]
Job losses
From the early days of the advancement of AI, there have actually been arguments advanced by ELIZA creator Joseph Weizenbaum and others about whether jobs that can be done by computers in fact should be done by them, offered the difference in between computers and humans, and between quantitative estimations and qualitative, value-based judgements. [120] In April 2023, it was reported that image generation AI has resulted in 70% of the jobs for video game illustrators in China being lost. [121] [122] In July 2023, developments in generative AI added to the 2023 Hollywood labor disputes. Fran Drescher, president of the Screen Actors Guild, stated that "artificial intelligence postures an existential threat to innovative occupations" during the 2023 SAG-AFTRA strike. [123] Voice generation AI has actually been viewed as a potential challenge to the voice acting sector. [124] [125]
The crossway of AI and work concerns among underrepresented groups globally remains a critical aspect. While AI guarantees performance improvements and ability acquisition, issues about job displacement and biased recruiting processes continue among these groups, as laid out in studies by Fast Company. To leverage AI for a more equitable society, proactive actions incorporate mitigating biases, advocating transparency, respecting privacy and authorization, and accepting varied teams and ethical considerations. Strategies include rerouting policy focus on policy, inclusive style, and education's potential for individualized mentor to take full advantage of benefits while decreasing harms. [126]
Racial and gender bias
Generative AI models can show and amplify any cultural predisposition present in the underlying data. For example, a language design might presume that doctors and judges are male, which secretaries or nurses are female, if those predispositions are common in the training information. [127] Similarly, an image design prompted with the text "a picture of a CEO" might disproportionately produce images of white male CEOs, [128] if trained on a racially biased data set. A variety of approaches for alleviating predisposition have actually been attempted, such as changing input prompts [129] and reweighting training data. [130]
Deepfakes
Deepfakes (a portmanteau of "deep learning" and "fake" [131] are AI-generated media that take an individual in an existing image or video and replace them with somebody else's similarity using artificial neural networks. [132] Deepfakes have actually amassed extensive attention and concerns for their usages in deepfake star pornographic videos, revenge pornography, fake news, hoaxes, health disinformation, monetary scams, and concealed foreign election disturbance. [133] [134] [135] [136] [137] [138] [139] This has actually generated reactions from both industry and government to find and limit their use. [140] [141]
In July 2023, the fact-checking company Logically found that the popular generative AI designs Midjourney, DALL-E 2 and Stable Diffusion would produce possible disinformation images when prompted to do so, such as images of electoral fraud in the United States and Muslim women supporting India's Hindu nationalist Bharatiya Janata Party. [142] [143]
In April 2024, a paper proposed to utilize blockchain (distributed journal innovation) to promote "transparency, verifiability, and decentralization in AI advancement and use". [144]
Audio deepfakes
Instances of users abusing software application to create controversial declarations in the vocal style of celebrities, public authorities, and other popular people have actually raised ethical concerns over voice generation AI. [145] [146] [147] [148] [149] [150] In reaction, business such as ElevenLabs have actually specified that they would deal with mitigating possible abuse through safeguards and identity verification. [151]
Concerns and fandoms have spawned from AI-generated music. The exact same software utilized to clone voices has been utilized on famous musicians' voices to develop songs that mimic their voices, getting both tremendous popularity and criticism. [152] [153] [154] Similar methods have actually also been used to develop enhanced quality or full-length versions of tunes that have actually been leaked or have yet to be launched. [155]
Generative AI has actually also been used to create brand-new digital artist characters, with a few of these getting adequate attention to receive record deals at major labels. [156] The developers of these virtual artists have actually likewise faced their reasonable share of criticism for their personified programs, consisting of reaction for "dehumanizing" an artform, and also producing artists which develop unrealistic or unethical attract their audiences. [157]
Cybercrime
Generative AI's ability to produce sensible phony material has actually been made use of in various types of cybercrime, consisting of phishing rip-offs. [158] Deepfake video and audio have been used to produce disinformation and fraud. In 2020, previous Google click fraud czar Shuman Ghosemajumder argued that once deepfake videos become perfectly reasonable, they would stop appearing exceptional to audiences, potentially leading to uncritical approval of incorrect details. [159] Additionally, big language models and other forms of text-generation AI have been utilized to create phony reviews of e-commerce websites to increase rankings. [160] Cybercriminals have actually created big language designs concentrated on fraud, including WormGPT and FraudGPT. [161]
A 2023 study revealed that generative AI can be vulnerable to jailbreaks, reverse psychology and timely injection attacks, enabling opponents to obtain assist with hazardous requests, such as for crafting social engineering and phishing attacks. [162] Additionally, other researchers have demonstrated that open-source models can be fine-tuned to remove their security restrictions at low expense. [163]
Reliance on market giants
Training frontier AI designs requires a huge amount of computing power. Usually only Big Tech business have the monetary resources to make such financial investments. Smaller start-ups such as Cohere and OpenAI wind up buying access to data centers from Google and Microsoft respectively. [164]
Energy and environment
Scientists and reporters have revealed issues about the environmental impact that the advancement and release of generative models are having: high CO2 emissions, [165] [166] [167] big quantities of freshwater used for data centers, [168] [169] and high quantities of electrical power usage. [170] [166] [171] There is also concern that these impacts might increase as these models are incorporated into extensively used search engines such as Google Search and Bing; [170] as chatbots and other applications become more popular; [170] [169] and as designs need to be retrained. [170]
Proposed mitigation methods include factoring possible environmental costs prior to design advancement or information collection, [165] increasing performance of information centers to decrease electricity/energy usage, [168] [170] [166] [169] [171] [167] developing more efficient maker finding out designs, [168] [166] [169] reducing the number of times that designs need to be re-trained, [167] developing a government-directed framework for auditing the environmental impact of these designs, [168] [167] regulating for transparency of these models, [167] regulating their energy and water use, [168] motivating researchers to publish information on their designs' carbon footprint, [170] [167] and increasing the number of topic experts who comprehend both device knowing and climate science. [167]
Content quality
The New York Times defines slop as analogous to spam: "shoddy or undesirable A.I. content in social networks, art, books and ... in search results page." [172] Journalists have actually expressed concerns about the scale of low-quality created material with respect to social media material small amounts, [173] the financial rewards from social media companies to spread such material, [173] [174] incorrect political messaging, [174] spamming of clinical research study paper submissions, [175] increased effort and time to discover higher quality or preferred material on the Internet, [176] the indexing of created material by online search engine, [177] and on journalism itself. [178]
A paper published by scientists at Amazon Web Services AI Labs discovered that over 57% of sentences from a sample of over 6 billion sentences from Common Crawl, a picture of websites, were device equated. A number of these automated translations were seen as lower quality, specifically for sentences that were translated across a minimum of three languages. Many lower-resource languages (ex. Wolof, Xhosa) were equated across more languages than higher-resource languages (ex. English, French). [179] [180]
In September 2024, Robyn Speer, the author of wordfreq, an open source database that calculated word frequencies based upon text from the Internet, revealed that she had actually stopped updating the information for several reasons: high costs for getting information from Reddit and Twitter, excessive concentrate on generative AI compared to other techniques in the natural language processing community, which "generative AI has polluted the data". [181]
The adoption of generative AI tools resulted in an explosion of AI-generated material across several domains. A research study from University College London approximated that in 2023, more than 60,000 scholarly articles-over 1% of all publications-were most likely composed with LLM assistance. [182] According to Stanford University's Institute for Human-Centered AI, roughly 17.5% of recently released computer system science documents and 16.9% of peer evaluation text now integrate content produced by LLMs. [183]
Visual material follows a comparable trend. Since the launch of DALL-E 2 in 2022, it is estimated that an average of 34 million images have been developed daily. As of August 2023, more than 15 billion images had actually been generated using text-to-image algorithms, with 80% of these produced by designs based on Stable Diffusion. [184]
If AI-generated material is consisted of in new data crawls from the Internet for extra training of AI designs, defects in the resulting models may happen. [185] Training an AI model specifically on the output of another AI model produces a lower-quality design. Repeating this procedure, where each brand-new model is trained on the previous design's output, causes progressive deterioration and ultimately leads to a "design collapse" after numerous models. [186] Tests have actually been conducted with pattern recognition of handwritten letters and with pictures of human faces. [187] As an effect, the value of data collected from authentic human interactions with systems may become progressively valuable in the existence of LLM-generated content in information crawled from the Internet.
On the other side, synthetic information is often utilized as an option to information produced by real-world occasions. Such data can be deployed to verify mathematical designs and to train device learning models while protecting user privacy, [188] including for structured data. [189] The technique is not limited to text generation; image generation has been utilized to train computer vision models. [190]
Misuse in journalism
In January 2023, Futurism.com broke the story that CNET had been utilizing an undisclosed internal AI tool to write at least 77 of its stories; after the news broke, CNET published corrections to 41 of the stories. [191]
In April 2023, the German tabloid Die Aktuelle published a fake AI-generated interview with former racing motorist Michael Schumacher, who had not made any public appearances given that 2013 after sustaining a brain injury in a snowboarding mishap. The story consisted of two possible disclosures: the cover consisted of the line "deceptively real", and the interview consisted of a recommendation at the end that it was AI-generated. The editor-in-chief was fired quickly afterwards in the middle of the debate. [192]
Other outlets that have published articles whose material and/or byline have been verified or believed to be developed by generative AI models - typically with false content, errors, and/or non-disclosure of generative AI usage - consist of:
- NewsBreak [193] [194]- outlets owned by Arena Group Sports Illustrated [195] TheStreet [195] Men's Journal [196]
The Columbus Dispatch [198] [199] Reviewed [200] USA Today [201]
Gizmodo [205] Jalopnik [205] A.V. Club [205] [206] Quartz [207]
Bankrate [209]
Yoga Journal [201] Backpacker [201] Clean Eating [201]
Miami Herald [201] Sacramento Bee [201] Tacoma News Tribune [201] The Rock Hill Herald [201] The Modesto Bee [201] Fort Worth Star-Telegram [201] Merced Sun-Star [201] Ledger-Enquirer [201] The Kansas City Star [201] Raleigh News & Observer [217]
PC Magazine [201] Mashable [201] AskMen [201]
Good Housekeeping [201]
People [201] Parents [201] Food & Wine [201] InStyle [201] Real Simple [201] Travel + Leisure [201] Better Homes & Gardens [201] Southern Living [201]
LA Weekly [218] The Village Voice [218]

In May 2024, Futurism kept in mind that a content management system video by AdVon Commerce, who had actually used generative AI to produce short articles for a number of the previously mentioned outlets, appeared to reveal that they "had produced 10s of thousands of short articles for more than 150 publishers." [201]
News broadcasters in Kuwait, Greece, South Korea, India, China and Taiwan have presented news with anchors based upon Generative AI models, triggering issues about job losses for human anchors and audience rely on news that has actually traditionally been affected by parasocial relationships with broadcasters, material creators or social media influencers. [220] [221] [222] Algorithmically produced anchors have actually also been utilized by allies of ISIS for their broadcasts. [223]
In 2023, Google apparently pitched a tool to news outlets that declared to "produce news stories" based on input information offered, such as "details of current events". Some news company executives who viewed the pitch described it as" [taking] for given the effort that went into producing accurate and artistic news stories." [224]
In February 2024, Google released a program to pay little publishers to compose 3 articles daily utilizing a beta generative AI model. The program does not require the understanding or consent of the sites that the publishers are using as sources, nor does it require the released short articles to be labeled as being developed or helped by these designs. [225]
Many defunct news sites (The Hairpin, The Frisky, Apple Daily, Ashland Daily Tidings, Clayton County Register, Southwest Journal) and blogs (The Unofficial Apple Weblog, iLounge) have undergone cybersquatting, with articles produced by generative AI. [226] [227] [228] [229] [230] [231] [232] [233]
United States Senators Richard Blumenthal and Amy Klobuchar have revealed concern that generative AI could have a hazardous effect on local news. [234] In July 2023, OpenAI partnered with the American Journalism Project to money local news outlets for explore generative AI, with Axios noting the possibility of generative AI business producing a dependence for these news outlets. [235]
Meta AI, a chatbot based on Llama 3 which summarizes newspaper article, was kept in mind by The Washington Post to copy sentences from those stories without direct attribution and to possibly further decrease the traffic of online news outlets. [236]
In action to potential risks around the use and misuse of generative AI in journalism and fret about decreasing audience trust, outlets worldwide, consisting of publications such as Wired, Associated Press, The Quint, Rappler or The Guardian have released guidelines around how they prepare to utilize and not utilize AI and generative AI in their work. [237] [238] [239] [240]
In June 2024, Reuters Institute released their Digital New Report for 2024. In a study of people in America and Europe, Reuters Institute reports that 52% and 47% respectively are uncomfortable with news produced by "mainly AI with some human oversight", and 23% and 15% respectively report being comfortable. 42% of Americans and 33% of Europeans reported that they were comfy with news produced by "primarily human with some assistance from AI". The results of global surveys reported that people were more unpleasant with news topics consisting of politics (46%), criminal offense (43%), and regional news (37%) produced by AI than other news topics. [241]
Computer shows portal
Technology portal
Artificial basic intelligence - Type of AI with wide-ranging abilities
Artificial imagination - Artificial simulation of human creativity
Expert system art - Visual media developed with AI
Artificial life - Field of study
Chatbot - Program that simulates discussion
Computational imagination - Multidisciplinary endeavour
Generative adversarial network - Deep knowing approach
Generative pre-trained transformer - Type of large language design
Large language design - Kind of machine knowing design
Music and synthetic intelligence - Usage of synthetic intelligence to generate music
Generative AI porn - Explicit product produced by generative AI
Procedural generation - Method in which information is produced algorithmically rather than manually
Retrieval-augmented generation - Type of details retrieval utilizing LLMs
Stochastic parrot - Term used in maker knowing
References
^ Newsom, Gavin; Weber, Shirley N. (September 5, 2023). "Executive Order N-12-23" (PDF). Executive Department, State of California. Archived (PDF) from the initial on February 21, 2024. Retrieved September 7, 2023.
^ Pinaya, Walter H. L.; Graham, Mark S.; Kerfoot, Eric; Tudosiu, Petru-Daniel; Dafflon, Jessica; Fernandez, Virginia; Sanchez, Pedro; Wolleb, Julia; da Costa, Pedro F.; Patel, Ashay (2023 ). "Generative AI for Medical Imaging: extending the MONAI Framework". arXiv:2307.15208 [eess.IV]
^ "What is ChatGPT, DALL-E, and generative AI?". McKinsey. Retrieved December 14, 2024.
^ "What is generative AI?". IBM. March 22, 2024.
^ Pasick, Adam (March 27, 2023). "Expert System Glossary: Neural Networks and Other Terms Explained". The New York City Times. ISSN 0362-4331. Archived from the initial on September 1, 2023. Retrieved April 22, 2023.
^ Karpathy, Andrej; Abbeel, Pieter; Brockman, Greg; Chen, Peter; Cheung, Vicki; Duan, Yan; Goodfellow, Ian; Kingma, Durk; Ho, Jonathan; Rein Houthooft; Tim Salimans; John Schulman; Ilya Sutskever; Wojciech Zaremba (June 16, 2016). "Generative designs". OpenAI. Archived from the original on November 17, 2023. Retrieved March 15, 2023.
^ a b Griffith, Erin; Metz, Cade (January 27, 2023). "Anthropic Said to Be Closing In on $300 Million in New A.I. Funding". The New York Times. Archived from the original on December 9, 2023. Retrieved March 14, 2023.
^ Lanxon, Nate; Bass, Dina; Davalos, Jackie (March 10, 2023). "A Cheat Sheet to AI Buzzwords and Their Meanings". Bloomberg News. Archived from the original on November 17, 2023. Retrieved March 14, 2023.
^ Metz, Cade (March 14, 2023). "OpenAI Plans to Up the Ante in Tech's A.I. Race". The New York Times. ISSN 0362-4331. Archived from the original on March 31, 2023. Retrieved March 31, 2023.
^ Thoppilan, Romal; De Freitas, Daniel; Hall, Jamie; Shazeer, Noam; Kulshreshtha, Apoorv (January 20, 2022). "LaMDA: Language Models for Dialog Applications". arXiv:2201.08239 [cs.CL]
^ Roose, Kevin (October 21, 2022). "A Coming-Out Party for Generative A.I., Silicon Valley's New Craze". The New York City Times. Archived from the initial on February 15, 2023. Retrieved March 14, 2023.
^ a b Metz, Cade (February 15, 2024). "OpenAI Unveils A.I. That Instantly Generates Eye-Popping Videos". The New York City Times. ISSN 0362-4331. Archived from the initial on February 15, 2024. Retrieved February 16, 2024.
^ "The race of the AI laboratories warms up". The Economist. January 30, 2023. Archived from the original on November 17, 2023. Retrieved March 14, 2023.
^ Yang, June; Gokturk, Burak (March 14, 2023). "Google Cloud brings generative AI to developers, services, and governments". Archived from the initial on November 17, 2023. Retrieved March 15, 2023.
^ Brynjolfsson, Erik; Li, Danielle; Raymond, Lindsey R. (April 2023), Generative AI at Work (Working Paper), Working Paper Series, doi:10.3386/ w31161, archived from the original on March 28, 2024, retrieved January 21, 2024
^ "Don't fear an AI-induced jobs apocalypse right now". The Economist. March 6, 2023. Archived from the original on November 17, 2023. Retrieved March 14, 2023.
^ Coyle, Jake (September 27, 2023). "In Hollywood writers' fight versus AI, humans win (in the meantime)". AP News. Associated Press. Archived from the original on April 3, 2024. Retrieved January 26, 2024.
^ Harreis, H.; Koullias, T.; Roberts, Roger. "Generative AI: Unlocking the future of style". Archived from the initial on November 17, 2023. Retrieved March 14, 2023.
^ "How Generative AI Can Augment Human Creativity". Harvard Business Review. June 16, 2023. ISSN 0017-8012. Archived from the initial on June 20, 2023. Retrieved June 20, 2023.
^ Hendrix, Justin (May 16, 2023). "Transcript: Senate Judiciary Subcommittee Hearing on Oversight of AI". techpolicy.press. Archived from the initial on November 17, 2023. Retrieved May 19, 2023.
^ Simon, Felix M.; Altay, Sacha; Mercier, Hugo (October 18, 2023). "Misinformation reloaded? Fears about the effect of generative AI on false information are overblown". Harvard Kennedy School Misinformation Review. doi:10.37016/ mr-2020-127. S2CID 264113883. Archived from the original on November 17, 2023. Retrieved November 16, 2023.
^ "New AI systems hit copyright law". BBC News. August 1, 2023. Retrieved September 28, 2024.
^ Newquist, H. P. (1994 ). The Brain Makers: Genius, Ego, And Greed In The Quest For Machines That Think. New York City: Macmillan/SAMS. pp. 45-53. ISBN 978-0-672-30412-5.
^ Sharkey, Noel (July 4, 2007), A programmable robotic from 60 AD, vol. 2611, New Scientist, archived from the original on January 13, 2018, obtained October 22, 2019
^ Brett, Gerard (July 1954), "The Automata in the Byzantine "Throne of Solomon"", Speculum, 29 (3 ): 477-487, doi:10.2307/ 2846790, ISSN 0038-7134, JSTOR 2846790, S2CID 163031682.
^ kelinich (March 8, 2014). "Maillardet's Automaton". The Franklin Institute. Archived from the original on August 24, 2023. Retrieved August 24, 2023.
^ Grinstead, Charles Miller; Snell, James Laurie (1997 ). Introduction to Probability. American Mathematical Society. pp. 464-466. ISBN 978-0-8218-0749-1.
^ Bremaud, Pierre (March 9, 2013). Markov Chains: Gibbs Fields, Monte Carlo Simulation, and Queues. Springer Science & Business Media. p. ix. ISBN 978-1-4757-3124-8. Archived from the initial on March 23, 2017.
^ Hayes, Brian (2013 ). "First Links in the Markov Chain". American Scientist. 101 (2 ): 92. doi:10.1511/ 2013.101.92. ISSN 0003-0996. Archived from the original on May 7, 2024. Retrieved September 24, 2023.
^ Fine, Shai; Singer, Yoram; Tishby, Naftali (July 1, 1998). "The Hierarchical Hidden Markov Model: Analysis and Applications". Artificial intelligence. 32 (1 ): 41-62. doi:10.1023/ A:1007469218079. ISSN 1573-0565. S2CID 3465810.
^ Crevier, Daniel (1993 ). AI: The Tumultuous Look For Expert System. New York City, New York City: BasicBooks. p. 109. ISBN 0-465-02997-3.
^ Bergen, Nathan; Huang, Angela (2023 ). "A Quick History of Generative AI" (PDF). Dichotomies: Generative AI: Navigating Towards a Much Better Future (2 ): 4. Archived (PDF) from the initial on August 10, 2023. Retrieved August 8, 2023.
^ a b Alting, Leo; Zhang, Hongchao (1989 ). "Computer assisted process planning: the modern study". The International Journal of Production Research. 27 (4 ): 553-585. doi:10.1080/ 00207548908942569. Archived from the initial on May 7, 2024. Retrieved October 3, 2023.
^ Chien, Steve (1998 ). "Automated planning and scheduling for goal-based autonomous spacecraft". IEEE Intelligent Systems and Their Applications. 13 (5 ): 50-55. doi:10.1109/ 5254.722362.
^ Burstein, Mark H., ed. (1994 ). ARPA/Rome Laboratory Knowledge-based Planning and Scheduling Initiative Workshop Proceedings. The Advanced Research Projects Agency, Department of Defense, and Rome Laboratory, US Air Force, Griffiss AFB. p. 219. ISBN 155860345X.
^ Pell, Barney; Bernard, Douglas E.; Chien, Steve A.; Gat, Erann; Muscettola, Nicola; Nayak, P. Pandurang; Wagner, Michael D.; Williams, Brian C. (1998 ). Bekey, George A. (ed.). An Autonomous Spacecraft Agent Prototype. Autonomous Robots Volume 5, No. 1. pp. 29-45. Our deliberator is a traditional generative AI planner based on the HSTS planning framework (Muscettola, 1994), and our control component is a conventional spacecraft attitude control system (Hackney et al. 1993). We likewise add an architectural part explicitly devoted to world modeling (the mode identifier), and compare control and tracking.
^ Jebara, Tony (2012 ). Artificial intelligence: discriminative and generative. Vol. 755. Springer Science & Business Media.
^ Cao, Yihan; Li, Siyu; Liu, Yixin; Yan, Zhiling; Dai, Yutong; Yu, Philip S.; Sun, Lichao (March 7, 2023). "A Thorough Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT". arXiv:2303.04226 [cs.AI]
^ "finetune-transformer-lm". GitHub. Archived from the initial on May 19, 2023. Retrieved May 19, 2023.
^ Radford, Alec; Wu, Jeffrey; Child, Rewon; Luan, David; Amodei, Dario; Sutskever, Ilya (2019 ). "Language designs are without supervision multitask learners" (PDF). OpenAI Blog.
^ Radford, Alec (June 11, 2018). "Improving language comprehending with without supervision knowing". OpenAI. Retrieved October 6, 2024.
^ Chandraseta, Rionaldi (January 21, 2021). "Generate Your Favourite Characters' Voice Lines utilizing Machine Learning". Towards Data Science. Retrieved December 18, 2024.
^ Temitope, Yusuf (December 10, 2024). "15. ai Creator exposes journey from MIT Project to internet phenomenon". The Guardian. Archived from the initial on December 28, 2024. Retrieved December 25, 2024.
^ Anirudh VK (March 18, 2023). "Deepfakes Are Elevating Meme Culture, But At What Cost?". Analytics India Magazine. Archived from the initial on December 26, 2024. Retrieved December 18, 2024. While AI voice memes have actually been around in some form considering that '15. ai' introduced in 2020, [...] ^ Coldewey, Devin (January 5, 2021). "OpenAI's DALL-E creates possible pictures of literally anything you ask it to". TechCrunch. Retrieved March 15, 2023.
^ "Stable Diffusion Public Release". Stability AI. Retrieved March 15, 2023.
^ Lock, Samantha (December 5, 2022). "What is AI chatbot phenomenon ChatGPT and could it replace people?". The Guardian. Retrieved March 15, 2023.
^ Huang, Haomiao (August 23, 2023). "How ChatGPT turned generative AI into an "anything tool"". Ars Technica. Retrieved September 21, 2024.
^ Bubeck, Sébastien; Chandrasekaran, Varun; Eldan, Ronen; Gehrke, Johannes; Horvitz, Eric; Kamar, Ece; Lee, Peter; Lee, Yin Tat; Li, Yuanzhi; Lundberg, Scott; Nori, Harsha; Palangi, Hamid; Ribeiro, Marco Tulio; Zhang, Yi (March 22, 2023). "Sparks of Artificial General Intelligence: Early explores GPT-4". arXiv:2303.12712 [cs.CL]
^ Schlagwein, Daniel; Willcocks, Leslie (September 13, 2023). "ChatGPT et al: The Ethics of Using (Generative) Artificial Intelligence in Research and Science". Journal of Infotech. 38 (2 ): 232-238. doi:10.1177/ 02683962231200411. S2CID 261753752.
^ "Meta open-sources multisensory AI model that integrates six kinds of data". May 9, 2023. Retrieved March 14, 2024.
^ Kruppa, Miles (December 6, 2023). "Google Announces AI System Gemini After Turmoil at Rival OpenAI". The Wall Street Journal. ISSN 0099-9660. Archived from the initial on December 6, 2023. Retrieved December 6, 2023.
^ Edwards, Benj (December 6, 2023). "Google releases Gemini-an effective AI design it states can exceed GPT-4". Ars Technica. Retrieved December 6, 2023.
^ Metz, Cade (February 8, 2024). "Google Releases Gemini, an A.I.-Driven Chatbot and Voice Assistant". The New York City Times. Retrieved February 8, 2024.
^ "Introducing the next generation of Claude". Retrieved March 4, 2024.
^ Nuñez, Michael (March 4, 2024). "Anthropic unveils Claude 3, surpassing GPT-4 and Gemini Ultra in benchmark tests". Venture Beat. Retrieved April 9, 2024.
^ Pierce, David (June 20, 2024). "Anthropic has a quick new AI design - and a clever new way to communicate with chatbots". The Verge. Retrieved June 22, 2024.
^ Baptista, Eduardo (July 9, 2024). "China leads the world in adoption of generative AI, survey programs". Reuters. Retrieved July 14, 2024.
^ "A History of Generative AI: From GAN to GPT-4". March 21, 2023. Archived from the initial on June 10, 2023. Retrieved April 28, 2023.
^ "Explainer: What is Generative AI, the technology behind OpenAI's ChatGPT?". Reuters. March 17, 2023. Archived from the initial on March 30, 2023. Retrieved March 17, 2023.
^ Roose, Kevin (February 16, 2023). "Bing's A.I. Chat: 'I Wished to Be Alive.'". The New York City Times. Archived from the initial on April 15, 2023. Retrieved January 30, 2024.
^ Bommasani, R.; Hudson, D. A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M. S.; Bohg, J.; Bosselut, A; Brunskill, E.; Brynjolfsson, E. (August 16, 2021). "On the opportunities and threats of foundation models". arXiv:2108.07258 [cs.LG]
^ Chen, Ming; Tworek, Jakub; Jun, Hongyu; Yuan, Qinyuan; Pinto, Hanyu Philippe De Oliveira; Kaplan, Jerry; Edwards, Haley; Burda, Yannick; Joseph, Nicholas; Brockman, Greg; Ray, Alvin (July 6, 2021). "Evaluating Large Language Models Trained on Code". arXiv:2107.03374 [cs.LG]
^ "Buying Cursor". Andreesen Horowitz.
^ Epstein, Ziv; Hertzmann, Aaron; Akten, Memo; Farid, Hany; Fjeld, Jessica; Frank, Morgan R. ; Groh, Matthew; Herman, Laura; Leach, Neil; Mahari, Robert; Pentland, Alex "Sandy"; Russakovsky, Olga; Schroeder, Hope; Smith, Amy (2023 ). "Art and the science of generative AI". Science. 380 (6650 ): 1110-1111. arXiv:2306.04141. Bibcode:2023 Sci ... 380.1110 E. doi:10.1126/ science.adh4451. PMID 37319193. S2CID 259095707.
^ Ramesh, Aditya; Pavlov, Mikhail; Goh, Gabriel; Gray, Scott; Voss, Chelsea; Radford, Alec; Chen, Mark; Sutskever, Ilya (2021 ). "Zero-shot text-to-image generation". International Conference on Machine Learning. PMLR. pp. 8821-8831.
^ Chandraseta, Rionaldi (January 21, 2021). "Generate Your Favourite Characters' Voice Lines using Machine Learning". Towards Data Science. Archived from the initial on January 21, 2021. Retrieved December 18, 2024.
^ Temitope, Yusuf (December 10, 2024). "15. ai Creator exposes journey from MIT Project to internet phenomenon". The Guardian. Archived from the initial on December 28, 2024. Retrieved December 25, 2024.
^ Ruppert, Liana (January 18, 2021). "Make Portal's GLaDOS And Other Beloved Characters Say The Weirdest Things With This App". Game Informer. Archived from the original on January 18, 2021. Retrieved December 18, 2024.
^ Kurosawa, Yuki (January 19, 2021). "ゲームキャラ音声読み上げソフト 15. ai 公開中 。 Undertale や Portal のキャラに好きなセリフを言ってもらえる" [Game Character Voice Reading Software "15. ai" Now Available. Get Characters from Undertale and Portal to Say Your Desired Lines] AUTOMATON (in Japanese). Archived from the original on January 19, 2021. Retrieved December 18, 2024. 英語版ボイスのみなので注意 。; もうひとつ15.aiの大きな特徴として挙げられるのが 、 豊かな感情表現だ 。 [Please note that only English voices are available.; Another major function of 15. ai is its rich emotional expression.] ^ Desai, Saahil (July 17, 2023). "A Voicebot Just Left Me Speechless". The Atlantic. Archived from the original on December 8, 2023. Retrieved November 28, 2023.
^ Agostinelli, Andrea; Denk, Timo I.; Borsos, Zalán; Engel, Jesse; Verzetti, Mauro; Caillon, Antoine; Huang, Qingqing; Jansen, Aren; Roberts, Adam; Tagliasacchi, Marco; Sharifi, Matt; Zeghidour, Neil; Frank, Christian (January 26, 2023). "MusicLM: Generating Music From Text". arXiv:2301.11325 [cs.SD]
^ Dalugdug, Mandy (August 3, 2023). "Meta in June stated that it used 20,000 hours of licensed music to train MusicGen, which included 10,000 "high-quality" certified music tracks. At the time, Meta's researchers outlined in a paper the ethical obstacles that they experienced around the development of generative AI designs like MusicGen". Archived from the original on August 15, 2023.
^ "Jay-Z's Delaware producer sparks argument over AI rights". Archived from the initial on February 27, 2024. Retrieved February 27, 2024.
^ "10 "Best" AI Music Generators (April 2024) - Unite.AI". October 19, 2022. Archived from the initial on January 29, 2024. Retrieved February 27, 2024.
^ Metz, Cade (April 4, 2023). "Instant Videos Could Represent the Next Leap in A.I. Technology". The New York Times. Archived from the initial on April 5, 2023. Retrieved April 5, 2023.
^ Wong, Queenie (September 29, 2022). "Facebook Parent Meta's AI Tool Can Create Artsy Videos From Text". cnet.com. Archived from the initial on April 5, 2023. Retrieved April 4, 2023.
^ Yang, Sherry; Du, Yilun (April 12, 2023). "UniPi: Learning universal policies by means of text-guided video generation". Google Research, Brain Team. Google AI Blog. Archived from the original on May 24, 2023.
^ Brohan, Anthony (2023 ). "RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control". arXiv:2307.15818 [cs.RO]
^ Abdullahi, Aminu (November 17, 2023). "10 Best Expert System (AI) 3D Generators". eWEEK. Archived from the original on May 7, 2024. Retrieved February 6, 2024.
^ "Slash CAD model develop times with brand-new AI-driven part production methodology|GlobalSpec". Archived from the initial on January 23, 2024. Retrieved February 6, 2024.
^ "The Role of Expert System (AI) in the CAD Industry". March 22, 2023. Archived from the original on February 9, 2024. Retrieved February 6, 2024.
^ Sabin, Sam (June 30, 2023). "GitHub has a vision to make code more protected by style". Axios Codebook. Archived from the initial on August 15, 2023. Retrieved August 15, 2023.
^ Vincent, James (March 20, 2023). "Text-to-video AI inches more detailed as startup Runway announces brand-new model". The Verge. Archived from the initial on September 27, 2023. Retrieved August 15, 2023. Text-to-video is the next frontier for generative AI, though present output is simple. Runway says it'll be making its brand-new generative video model, Gen-2, offered to users in 'the coming weeks.'
^ Vanian, Jonathan (March 16, 2023). "Microsoft includes OpenAI innovation to Word and Excel". CNBC. Archived from the initial on August 15, 2023. Retrieved August 15, 2023. Microsoft is bringing generative artificial intelligence technologies such as the popular ChatGPT chatting app to its Microsoft 365 suite of business software application ... the brand-new A.I. functions, called Copilot, will be readily available in some of the business's most popular company apps, including Word, PowerPoint and Excel.
^ Wilson, Mark (August 15, 2023). "The app's Memories feature just got a big upgrade". TechRadar. Archived from the initial on August 15, 2023. The Google Photos app is getting a revamped, AI-powered Memories function ... you'll have the ability to utilize generative AI to come up with some recommended names like "a desert adventure".
^ Sullivan, Laurie (May 23, 2023). "Adobe Adds Generative AI To Photoshop". MediaPost. Archived from the original on August 15, 2023. Retrieved August 15, 2023. Generative synthetic intelligence (AI) will turn into one of the most important features for innovative designers and online marketers. Adobe on Tuesday unveiled a Generative Fill feature in Photoshop to bring Firefly's AI abilities into style.
^ Michael Nuñez (July 19, 2023). "LLaMA 2: How to access and usage Meta's versatile open-source chatbot today". VentureBeat. Archived from the original on November 3, 2023. Retrieved August 15, 2023. If you wish to run LLaMA 2 on your own device or modify the code, you can download it straight from Hugging Face, a leading platform for sharing AI designs.
^ Pounder, Les (March 25, 2023). "How To Create Your Own AI Chatbot Server With Raspberry Pi 4". Archived from the initial on August 15, 2023. Retrieved August 15, 2023. Using a Pi 4 with 8GB of RAM, you can produce a ChatGPT-like server based upon LLaMA.
^ Kemper, Jonathan (November 10, 2022). ""Draw Things" App brings Stable Diffusion to the iPhone". The Decoder. Archived from the initial on August 15, 2023. Retrieved August 15, 2023. Draw Things is an app that brings Stable Diffusion to the iPhone. The AI images are created in your area, so you don't need a Web connection.
^ Witt, Allan (July 7, 2023). "Best Computer to Run LLaMA AI Model in your home (GPU, CPU, RAM, SSD)". Archived from the original on August 15, 2023. Retrieved August 15, 2023. To run LLaMA model in your home, you will need a computer system construct with an effective GPU that can deal with the big quantity of data and calculation needed for inferencing.
^ Westover, Brian (September 28, 2023). "Who Needs ChatGPT? How to Run Your Own Free and Private AI Chatbot". Ziff Davis. Archived from the original on January 7, 2024. Retrieved January 7, 2024.
^ @karpathy (December 20, 2023). "I practically only trust 2 LLM evals today" (Tweet) - by means of Twitter.
^ @ylecun (January 5, 2024). "Nabla's shift from ChatGPT to open source LLMs ..." (Tweet) - by means of Twitter.
^ @ylecun (November 1, 2023). "Open source platforms * increase * security and security" (Tweet) - by means of Twitter.
^ Nellis, Stephen; Lee, Jane (September 1, 2022). "U.S. authorities order Nvidia to stop sales of leading AI chips to China". Reuters. Archived from the initial on August 15, 2023. Retrieved August 15, 2023.
^ Shilov, Anton (May 7, 2023). "Nvidia's Chinese A800 GPU's Performance Revealed". Tom's Hardware. Archived from the initial on May 7, 2024. Retrieved August 15, 2023. the A800 operates at 70% of the speed of A100 GPUs while complying with strict U.S. export requirements that restrict how much processing power Nvidia can offer.
^ Patel, Dylan (October 24, 2022). "How China's Biren Is Attempting To Evade US Sanctions". Archived from the original on August 15, 2023. Retrieved August 15, 2023.
^ "5 free software to identify fake AI-generated images" (in Italian). October 28, 2023. Archived from the original on October 29, 2023. Retrieved October 29, 2023.
^ "Detecting AI finger prints: A guide to watermarking and beyond". Brookings Institution. January 4, 2024. Archived from the original on September 3, 2024. Retrieved September 5, 2024.
^ Fowler, Geoffrey (April 3, 2023). "We tested a new ChatGPT-detector for teachers. It flagged an innocent student". washingtonpost.com. Archived from the original on March 28, 2024. Retrieved February 6, 2024.
^ Fowler, Geoffrey (June 2, 2023). "Detecting AI may be difficult. That's a big issue for instructors". washingtonpost.com. Archived from the original on June 3, 2023. Retrieved February 6, 2024.
^ Bartz, Diane; Hu, Krystal (July 21, 2023). "OpenAI, Google, others promise to watermark AI material for security, White House states". Reuters. Archived from the initial on July 27, 2023.
^ "FACT SHEET: President Biden Issues Executive Order on Safe, Secure, and Trustworthy Artificial Intelligence". The White House. October 30, 2023. Archived from the original on January 30, 2024. Retrieved January 30, 2024.
^ Burt, Andrew (October 31, 2023). "3 Obstacles to Regulating Generative AI". Harvard Business Review. ISSN 0017-8012. Archived from the original on February 17, 2024. Retrieved February 17, 2024.
^ "EU AI Act: very first guideline on artificial intelligence". European Parliament. August 6, 2023. Retrieved September 13, 2024.
^ Chee, Foo Yun; Mukherjee, Supantha (June 14, 2023). "EU legislators vote for harder AI rules as draft relocations to final phase". Reuters. Archived from the original on July 27, 2023. Retrieved July 26, 2023.
^ Ye, Josh (July 13, 2023). "China says generative AI guidelines to use just to items for the general public". Reuters. Archived from the initial on July 27, 2023. Retrieved July 13, 2023.
^ "生成式人工智能服务管理暂行办法". July 13, 2023. Archived from the initial on July 27, 2023. Retrieved July 27, 2023.
^ a b "Generative Expert system and Copyright Law". Congressional Research Service. LSB10922. September 29, 2023. Archived from the original on March 22, 2024. Retrieved January 30, 2024.
^ Thompson, Stuart (January 25, 2024). "We Asked A.I. to Create the Joker. It Generated a Copyrighted Image". The New York Times. Archived from the original on January 25, 2024. Retrieved January 26, 2024.
^ Hadero, Haleluya; Bauder, David (December 27, 2023). "The New York Times sues OpenAI and Microsoft for utilizing its stories to train chatbots". Associated Press News. AP News. Archived from the original on December 27, 2023. Retrieved April 13, 2023.
^ O'Brien, Matt (September 25, 2023). "Photo huge Getty took a leading AI image-maker to court. Now it's also welcoming the innovation". AP NEWS. Associated Press. Archived from the initial on January 30, 2024. Retrieved January 30, 2024.
^ Barber, Gregory (December 9, 2023). "The Generative AI Copyright Fight Is Just Starting". Wired. Archived from the initial on January 19, 2024. Retrieved January 19, 2024.
^ Bruell, Alexandra (December 27, 2023). "New York Times Sues Microsoft and OpenAI, Alleging Copyright Infringement". Wall Street Journal. Archived from the initial on January 18, 2024. Retrieved January 19, 2024.
^ Brittain, Blake (August 21, 2023). "AI-generated art can not get copyrights, US court says". Reuters. Archived from the original on January 20, 2024. Retrieved January 19, 2024.
^ David, Emilla (August 29, 2023). "US Copyright Office desires to hear what individuals think about AI and copyright". The Verge. Archived from the original on January 19, 2024. Retrieved January 19, 2024.
^ "Secretary-General's remarks to the Security Council on Artificial Intelligence". un.org. July 18, 2023. Archived from the original on July 28, 2023. Retrieved July 27, 2023.
^ "The Writers Strike Is Deciding on AI". Time. May 4, 2023. Archived from the original on June 11, 2023. Retrieved June 11, 2023.
^ Tarnoff, Ben (August 4, 2023). "Lessons from Eliza". The Guardian Weekly. pp. 34-39.
^ Zhou, Viola (April 11, 2023). "AI is already taking computer game illustrators' jobs in China". Rest of World. Archived from the original on August 13, 2023. Retrieved August 17, 2023.
^ Carter, Justin (April 11, 2023). "China's game art industry reportedly annihilated by growing AI utilize". Game Developer. Archived from the original on August 17, 2023. Retrieved August 17, 2023.
^ Collier, Kevin (July 14, 2023). "Actors vs. AI: Strike brings focus to emerging use of advanced tech". NBC News. Archived from the original on July 20, 2023. Retrieved July 21, 2023. SAG-AFTRA has actually signed up with the Writer's [sic] Guild of America in requiring a contract that clearly demands AI policies to secure writers and the works they create. ... The future of generative expert system in Hollywood-and how it can be utilized to replace labor-has become a crucial sticking point for stars going on strike. In a press conference Thursday, Fran Drescher, president of the Screen Actors Guild-American Federation of Television and Radio Artists (more commonly understood as SAG-AFTRA), stated that 'expert system poses an existential risk to imaginative occupations, and all actors and performers are worthy of agreement language that safeguards them from having their identity and skill exploited without permission and pay.'
^ Wiggers, Kyle (August 22, 2023). "ElevenLabs' voice-generating tools launch out of beta". TechCrunch. Archived from the initial on November 28, 2023. Retrieved September 25, 2023.
^ Shrivastava, Rashi. "'Keep Your Paws Off My Voice': Voice Actors Worry Generative AI Will Steal Their Livelihoods". Forbes. Archived from the original on December 2, 2023. Retrieved November 28, 2023.
^ Gupta, Shalene (October 31, 2023). "Underrepresented groups in countries all over the world are stressed over AI being a risk to tasks". Fast Company. Archived from the original on December 8, 2023. Retrieved December 8, 2023.
^ Rachel Gordon (March 3, 2023). "Large language models are prejudiced. Can logic assist in saving them?". MIT CSAIL. Archived from the original on January 23, 2024. Retrieved January 26, 2024.
^ OpenAI (July 18, 2022). "Reducing bias and improving safety in DALL · E 2". OpenAI. Archived from the original on January 26, 2024. Retrieved January 26, 2024.
^ Jake Traylor (July 27, 2022). "No quick fix: How OpenAI's DALL · E 2 showed the challenges of predisposition in AI". NBC News. Archived from the original on January 26, 2024. Retrieved January 26, 2024.
^ "DALL · E 2 pre-training mitigations". OpenAI. June 28, 2022. Archived from the initial on January 26, 2024. Retrieved January 26, 2024.
^ Brandon, John (February 16, 2018). "Terrifying high-tech porn: Creepy 'deepfake' videos are on the rise". Fox News. Archived from the initial on June 15, 2018. Retrieved February 20, 2018.
^ Cole, Samantha (January 24, 2018). "We Are Truly Fucked: Everyone Is Making AI-Generated Fake Porn Now". Vice. Archived from the initial on September 7, 2019. Retrieved May 4, 2019.
^ "What Are Deepfakes & Why the Future of Porn is Terrifying". Highsnobiety. February 20, 2018. Archived from the initial on July 14, 2021. Retrieved February 20, 2018.
^ "Experts fear face swapping tech might begin an international face-off". The Outline. Archived from the original on January 16, 2020. Retrieved February 28, 2018.
^ Roose, Kevin (March 4, 2018). "Here Come the Fake Videos, Too". The New York City Times. ISSN 0362-4331. Archived from the initial on June 18, 2019. Retrieved March 24, 2018.
^ Schreyer, Marco; Sattarov, Timur; Reimer, Bernd; Borth, Damian (2019 ). "Adversarial Learning of Deepfakes in Accounting". arXiv:1910.03810 [cs.LG]
^ Menz, Bradley (2024 ). "Health Disinformation Use Case Highlighting the Urgent Need for Expert System Vigilance". JAMA Internal Medicine. 184 (1 ): 92-96. doi:10.1001/ jamainternmed.2023.5947. PMID 37955873. S2CID 265148637. Archived from the original on February 4, 2024. Retrieved February 4, 2024.
^ Chalfant, Morgan (March 6, 2024). "U.S. braces for foreign disturbance in 2024 election". Semafor. Archived from the initial on March 11, 2024. Retrieved March 6, 2024.
^ Menn, Joseph (September 23, 2024). "Russia, Iran utilize AI to boost anti-U.S. influence projects, officials state". The Washington Post. ISSN 0190-8286. Archived from the original on September 24, 2024. Retrieved September 23, 2024.
^ "Join the Deepfake Detection Challenge (DFDC)". deepfakedetectionchallenge.ai. Archived from the initial on January 12, 2020. Retrieved November 8, 2019.
^ Clarke, Yvette D. (June 28, 2019). "H.R. 3230 - 116th Congress (2019-2020): Defending Each and Every Person from False Appearances by Keeping Exploitation Subject to Accountability Act of 2019". www.congress.gov. Archived from the original on December 17, 2019. Retrieved October 16, 2019.
^ "New Research Reveals Scale of Threat Posed by AI-generated Images on 2024 Elections". Logically. July 27, 2023. Archived from the initial on October 3, 2023. Retrieved July 6, 2024.
^ Lawton, Graham (September 12, 2023). "Disinformation wars: The battle against phony news in the age of AI". New Scientist. Retrieved July 5, 2024.
^ Brewer, Jordan; Patel, Dhru; Kim, Dennie; Murray, Alex (April 12, 2024). "Navigating the difficulties of generative innovations: Proposing the integration of expert system and blockchain". Business Horizons. 67 (5 ): 525-535. doi:10.1016/ j.bushor.2024.04.011. ISSN 0007-6813.
^ "People Are Still Terrible: AI Voice-Cloning Tool Misused for Deepfake Celeb Clips". PCMag Middle East. January 31, 2023. Archived from the initial on December 25, 2023. Retrieved July 25, 2023.
^ "The generative A.I. software race has started". Fortune. Archived from the initial on March 25, 2023. Retrieved February 3, 2023.
^ Milmo, Dan; Hern, Alex (May 20, 2023). "Elections in UK and US at risk from AI-driven disinformation, say specialists". The Guardian. ISSN 0261-3077. Archived from the original on November 16, 2023. Retrieved July 25, 2023.
^ "Seeing is thinking? Global scramble to deal with deepfakes". news.yahoo.com. Archived from the original on February 3, 2023. Retrieved February 3, 2023.
^ Vincent, James (January 31, 2023). "4chan users accept AI voice clone tool to create celebrity hatespeech". The Verge. Archived from the initial on December 3, 2023. Retrieved February 3, 2023.
^ Thompson, Stuart A. (March 12, 2023). "Making Deepfakes Gets Cheaper and Easier Thanks to A.I." The New York City Times. ISSN 0362-4331. Archived from the original on October 29, 2023. Retrieved July 25, 2023.
^ "A brand-new AI voice tool is currently being abused to make deepfake celeb audio clips". Engadget. January 31, 2023. Archived from the original on October 10, 2023. Retrieved February 3, 2023.
^ Gee, Andre (April 20, 2023). "Just Because AI-Generated Rap Songs Go Viral Doesn't Mean They're Good". Rolling Stone. Archived from the original on January 2, 2024. Retrieved December 6, 2023.
^ Coscarelli, Joe (April 19, 2023). "An A.I. Hit of Fake 'Drake' and 'The Weeknd' Rattles the Music World". The New York Times. Archived from the original on May 15, 2023. Retrieved December 5, 2023.
^ Lippiello, Emily; Smith, Nathan; Pereira, Ivan (November 3, 2023). "AI songs that mimic popular artists raising alarms in the music market". ABC News. Archived from the initial on December 6, 2023. Retrieved December 6, 2023.
^ Skelton, Eric. "Fans Are Using Artificial Intelligence to Turn Rap Snippets Into Full Songs". Complex. Archived from the initial on January 2, 2024. Retrieved December 6, 2023.
^ Marr, Bernard. "Virtual Influencer Noonoouri Lands Record Deal: Is She The Future Of Music?". Forbes. Archived from the initial on December 4, 2023. Retrieved December 6, 2023.
^ Thaler, Shannon (September 8, 2023). "Warner Music indications first-ever record handle AI pop star". New York Post. Archived from the initial on December 15, 2023. Retrieved December 6, 2023.
^ Sjouwerman, Stu (December 26, 2022). "Deepfakes: Prepare yourself for phishing 2.0". Fast Company. Archived from the initial on July 31, 2023. Retrieved July 31, 2023.
^ Sonnemaker, Tyler. "As social networks platforms brace for the incoming wave of deepfakes, Google's previous 'scams czar' anticipates the most significant danger is that deepfakes will ultimately end up being dull". Business Insider. Archived from the initial on April 14, 2021. Retrieved July 31, 2023.
^ Collinson, Patrick (July 15, 2023). "Fake reviews: can we trust what we read online as use of AI takes off?". The Guardian. ISSN 0261-3077. Archived from the original on November 22, 2023. Retrieved December 6, 2023.
^ "After WormGPT, FraudGPT Emerges to Help Scammers Steal Your Data". PCMAG. July 25, 2023. Archived from the initial on July 31, 2023. Retrieved July 31, 2023.
^ Gupta, Maanak; Akiri, Charankumar; Aryal, Kshitiz; Parker, Eli; Praharaj, Lopamudra (2023 ). "From ChatGPT to ThreatGPT: Impact of Generative AI in Cybersecurity and Privacy". IEEE Access. 11: 80218-80245. arXiv:2307.00691. Bibcode:2023 IEEEA..1180218 G. doi:10.1109/ ACCESS.2023.3300381. S2CID 259316122.
^ Piper, Kelsey (February 2, 2024). "Should we make our most effective AI designs open source to all?". Vox. Retrieved January 13, 2025.
^ Metz, Cade (July 10, 2023). "In the Age of A.I., Tech's Little Guys Need Big Friends". New York City Times.
^ a b Bender, Emily M.; Gebru, Timnit; McMillan-Major, Angelina; Shmitchell, Shmargaret (March 1, 2021). "On the Dangers of Stochastic Parrots: Can Language Models be Too Big?". Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. FAccT '21. New York, NY, USA: Association for Computing Machinery. pp. 610-623. doi:10.1145/ 3442188.3445922. ISBN 978-1-4503-8309-7.
^ a b c d "AI is an energy hog. This is what it implies for climate change". MIT Technology Review. May 23, 2024. Archived from the original on August 20, 2024. Retrieved August 27, 2024.
^ a b c d e f g Dhar, Payal (August 1, 2020). "The carbon effect of artificial intelligence". Nature Machine Intelligence. 2 (8 ): 423-425. doi:10.1038/ s42256-020-0219-9. ISSN 2522-5839. Archived from the original on August 14, 2024.
^ a b c d e Crawford, Kate (February 20, 2024). "Generative AI's ecological costs are soaring - and primarily secret". Nature. 626 (8000 ): 693. Bibcode:2024 Natur.626..693 C. doi:10.1038/ d41586-024-00478-x. PMID 38378831. Archived from the initial on August 22, 2024.
^ a b c d Rogers, Reece. "AI's Energy Demands Are Out of Control. Welcome to the Internet's Hyper-Consumption Era". Wired. ISSN 1059-1028. Archived from the initial on August 14, 2024. Retrieved August 27, 2024.
^ a b c d e f Saenko, Kate (May 23, 2023). "Is generative AI bad for the environment? A computer researcher describes the carbon footprint of ChatGPT and its cousins". The Conversation. Archived from the initial on July 1, 2024. Retrieved August 27, 2024.
^ a b Lohr, Steve (August 26, 2024). "Will A.I. Ruin the Planet or Save the Planet?". The New York City Times. ISSN 0362-4331. Archived from the original on August 26, 2024. Retrieved August 27, 2024.
^ Hoffman, Benjamin (June 11, 2024). "First Came 'Spam.' Now, With A.I., We've Got 'Slop'". The New York City Times. ISSN 0362-4331. Archived from the original on August 26, 2024. Retrieved August 27, 2024.
^ a b "Investigation Finds Actual Source of All That AI Slop on Facebook". Futurism. August 10, 2024. Archived from the original on August 15, 2024. Retrieved August 27, 2024.
^ a b Warzel, Charlie (August 21, 2024). "The MAGA Aesthetic Is AI Slop". The Atlantic. Archived from the initial on August 25, 2024. Retrieved August 27, 2024.
^ Edwards, Benj (August 14, 2024). "Research AI model suddenly attempts to modify its own code to extend runtime". Ars Technica. Archived from the initial on August 24, 2024. Retrieved August 27, 2024.
^ Hern, Alex; Milmo, Dan (May 19, 2024). "Spam, junk ... slop? The newest wave of AI behind the 'zombie web'". The Guardian. ISSN 0261-3077. Archived from the initial on August 26, 2024. Retrieved August 27, 2024.
^ Cox, Joseph (January 18, 2024). "Google News Is Boosting Garbage AI-Generated Articles". 404 Media. Archived from the original on June 13, 2024. Retrieved August 27, 2024.
^ "Beloved Local Newspapers Fired Staffers, Then Started Running AI Slop". Futurism. July 31, 2024. Archived from the initial on August 12, 2024. Retrieved August 27, 2024.
^ Thompson, Brian; Dhaliwal, Mehak; Frisch, Peter; Domhan, Tobias; Federico, Marcello (August 2024). Ku, Lun-Wei; Martins, Andre; Srikumar, Vivek (eds.). "A Stunning Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism". Findings of the Association for Computational Linguistics ACL 2024. Bangkok, Thailand and virtual conference: Association for Computational Linguistics: 1763-1775. arXiv:2401.05749. doi:10.18653/ v1/2024. findings-acl.103.
^ Roscoe, Jules (January 17, 2024). "A 'Shocking' Amount of the Web Is Already AI-Translated Trash, Scientists Determine". VICE. Archived from the initial on July 1, 2024. Retrieved August 27, 2024.
^ Koebler, Jason (September 19, 2024). "Project Analyzing Human Language Usage Shuts Down Because 'Generative AI Has Polluted the Data'". 404 Media. Archived from the initial on September 19, 2024. Retrieved September 20, 2024. While there has constantly been spam on the internet and in the datasets that Wordfreq used, "it was manageable and frequently identifiable. Large language designs produce text that masquerades as genuine language with intent behind it, despite the fact that there is none, and their output appear all over," she wrote. She provides the example that ChatGPT overuses the word "dive," in a manner that people do not, which has actually tossed off the frequency of this particular word.
^ Gray, Andrew (March 24, 2024). "ChatGPT "contamination": estimating the frequency of LLMs in the scholarly literature". arXiv:2403.16887 [cs.DL]
^ Kannan, Prabha (May 13, 2024). "How Much Research Is Being Written by Large Language Models?". Human-Centered Expert System. Stanford University. Retrieved August 16, 2024.
^ Valyaeva, Alina (August 15, 2023). "AI Image Statistics for 2024: How Much Content Was Created by AI". Everypixel Journal. Retrieved August 16, 2024.
^ Shumailov, Ilia; Shumaylov, Zakhar; Zhao, Yiren; Papernot, Nicolas; Anderson, Ross; Gal, Yarin (July 2024). "AI models collapse when trained on recursively generated data". Nature. 631 (8022 ): 755-759. Bibcode:2024 Natur.631..755 S. doi:10.1038/ s41586-024-07566-y. PMC 11269175. PMID 39048682.
^ Bhatia, Aatish (August 26, 2024). "When A.I.'s Output Is a Hazard to A.I. Itself". The New York City Times. ISSN 0362-4331. Retrieved August 27, 2024.
^ "Self-Consuming Generative Models Go Mad". ICLR. 2024.
^ Owen, Sean (April 12, 2023). "Synthetic Data for Better Artificial Intelligence". databricks.com. Archived from the initial on January 3, 2024. Retrieved January 4, 2024.
^ Sharma, Himanshu (July 11, 2023). "Synthetic Data Platforms: Unlocking the Power of Generative AI for Structured Data". kdnuggets.com. Archived from the original on January 3, 2024. Retrieved January 4, 2024.
^ Stöckl, Andreas (November 2, 2022). "Evaluating an Artificial Image Dataset Generated with Stable Diffusion". arXiv:2211.01777 [cs.CV]
^ Roth, Emma (January 25, 2023). "CNET found errors in majority of its AI-written stories". The Verge. Archived from the original on November 6, 2023. Retrieved June 17, 2023.
^ "A publication touted Michael Schumacher's very first interview in years. It was really AI". NPR. April 28, 2023. Archived from the initial on June 17, 2023. Retrieved June 17, 2023.
^ Al-Sibai, Noor (January 3, 2024). "Police Say AI-Generated Article About Local Murder Is "Entirely" Comprised". Futurism. Archived from the initial on January 5, 2024. Retrieved January 8, 2024.
^ "NewsBreak: Most downloaded US news app has Chinese roots and 'writes fiction' utilizing AI". Reuters. June 5, 2024. Archived from the original on June 6, 2024. Retrieved June 7, 2024.
^ a b Harrison, Maggie (November 27, 2023). "Sports Illustrated Published Articles by Fake, AI-Generated Writers". Futurism. Archived from the original on December 15, 2023. Retrieved January 8, 2024.
^ Christian, Jon (February 9, 2023). "Magazine Publishes Serious Errors in First AI-Generated Health Article". Futurism. Archived from the initial on December 26, 2023. Retrieved January 8, 2024.
^ Schneider, Jaron (December 14, 2023). "B&H Photo Published an AI-Generated Guide Written by a Phony Person". PetaPixel. Archived from the original on January 4, 2024. Retrieved January 8, 2024.
^ Harrison, Maggie (August 29, 2023). "USA Today Owner Pauses AI Articles After Butchering Sports Coverage". Futurism. Archived from the original on January 4, 2024. Retrieved January 8, 2024.
^ Buchanan, Tyler (August 28, 2023). "Dispatch pauses AI sports writing program". Axios. Archived from the original on January 1, 2024. Retrieved January 8, 2024.
^ Sommer, Will (October 26, 2023). "Mysterious bylines appeared on an U.S.A. Today website. Did these authors exist?". Washington Post. ISSN 0190-8286. Archived from the original on October 26, 2023. Retrieved January 8, 2024. ^ a b c d e f g h i j k l m n o p q r s t u v w x y z aa ab a/c "Meet AdVon, the AI-Powered Content Monster Infecting the Media Industry". Futurism. May 8, 2024. Archived from the initial on June 4, 2024. Retrieved June 8, 2024.
^ O'Sullivan, Donie; Gordon, Allison (November 2, 2023). "How Microsoft's AI is making a mess of the news|CNN Business". CNN. Archived from the original on November 2, 2023. Retrieved January 8, 2024.
^ Meade, Amanda (July 31, 2023). "News Corp utilizing AI to produce 3,000 Australian local newspaper article a week". The Guardian. ISSN 0261-3077. Archived from the original on December 2, 2023. Retrieved January 8, 2024.
^ Tangermann, Victor (June 30, 2023). "Gizmodo Staff Furious After Site Announces Transfer To AI Content". Futurism. Archived from the initial on December 6, 2023. Retrieved January 8, 2024.
^ a b c Kafka, Peter (July 18, 2023). "Coming to your internet, whether you like it or not: More AI-generated stories". Vox. Archived from the original on July 18, 2023. Retrieved January 8, 2024.
^ Landymore, Frank; Christian, Jon (September 13, 2023). "The A.V. Club's AI-Generated Articles Are Copying Directly From IMDb". Futurism. Archived from the original on December 6, 2023. Retrieved January 8, 2024.
^ Stiaplame, Nordiisk (January 28, 2025). "Quartz Is Publishing AI-Generated Articles Based on Other AI Slop, In Addition To Warning They May Be Filled With Errors". Futurism. Archived from the initial on January 29, 2025. Retrieved January 30, 2025.
^ Carroll, Rory (May 14, 2023). "Irish Times apologises for scam AI article about women's usage of phony tan". The Guardian. ISSN 0261-3077. Archived from the original on May 14, 2023. Retrieved January 8, 2024.
^ Christian, Jon (February 1, 2023). "CNET Sister Site Restarts AI Articles, Immediately Publishes Idiotic Error". Futurism. Archived from the original on November 27, 2023. Retrieved January 8, 2024.
^ Al-Sibai, Noor; Christian, Jon (March 30, 2023). "BuzzFeed Is Quietly Publishing Entire AI-Generated Articles". Futurism. Archived from the initial on December 6, 2023. Retrieved January 8, 2024.
^ "Newsweek is making generative AI a component in its newsroom". Nieman Lab. April 17, 2024. Archived from the initial on May 15, 2024. Retrieved May 24, 2024.
^ "What remains in a byline? For Hoodline's AI-generated local news, whatever - and nothing". Nieman Lab. June 3, 2024. Archived from the initial on June 6, 2024. Retrieved June 8, 2024.
^ "AI-generated news is here from S.F.-based Hoodline. What does that mean for conventional publishers?". San Francisco Chronicle. May 8, 2024. Archived from the initial on June 5, 2024. Retrieved June 7, 2024.
^ Gold, Hadas (May 30, 2024). "A nationwide network of regional news sites is publishing AI-written short articles under phony bylines. Experts are raising alarm". CNN. Archived from the original on June 6, 2024. Retrieved June 8, 2024.
^ "Wyoming press reporter caught utilizing expert system to develop fake quotes and stories". Associated Press. August 14, 2024. Archived from the initial on August 24, 2024. Retrieved August 27, 2024.
^ "Cosmos Magazine releases AI-generated posts, drawing criticism from journalists, co-founders". ABC News. August 7, 2024. Archived from the initial on August 24, 2024. Retrieved August 27, 2024.
^ "AI-generated posts are permeating major news publications". National Public Radio. May 16, 2024. Archived from the initial on June 19, 2024. Retrieved July 8, 2024.
^ a b c Knibbs, Kate (July 30, 2024). "Zombie Alt-Weeklies Are Stuffed With AI Slop About OnlyFans". Wired. Archived from the initial on August 11, 2024. Retrieved August 27, 2024.
^ "Apple states it will upgrade AI function after incorrect news signals". The Guardian. January 7, 2025. Archived from the original on January 14, 2025. Retrieved January 14, 2025.
^ "TV channels are using AI-generated presenters to check out the news. The concern is, will we trust them?". BBC News. January 26, 2024. Archived from the original on January 26, 2024. Retrieved May 24, 2024.
^ Tait, Amelia (October 20, 2023). "'Here is the news. You can't stop us': AI anchor Zae-In grants us an interview". The Guardian. ISSN 0261-3077. Archived from the initial on January 28, 2024. Retrieved May 24, 2024.
^ Kuo, Lily (November 9, 2018). "World's first AI news anchor unveiled in China". The Guardian. ISSN 0261-3077. Archived from the initial on February 20, 2024. Retrieved May 24, 2024.
^ "These ISIS news anchors are AI fakes. Their propaganda is genuine". Washington Post. May 17, 2024. Archived from the initial on May 19, 2024. Retrieved May 24, 2024.
^ Mullin, Benjamin; Grant, Nico (July 20, 2023). "Google Tests A.I. Tool That Is Able to Write News Articles". The New York City Times. ISSN 0362-4331. Archived from the initial on May 16, 2024. Retrieved May 24, 2024.
^ Stenberg, Mark (February 27, 2024). "Google Is Paying Publishers Five-Figure Sums to Test an Unreleased Gen AI Platform". Adweek. Archived from the initial on March 9, 2024. Retrieved April 17, 2024.
^ Knibbs, Kate (February 7, 2024). "Confessions of an AI Clickbait Kingpin". Wired. ISSN 1059-1028. Archived from the initial on May 18, 2024. Retrieved May 24, 2024.
^ Knibbs, Kate (January 26, 2024). "How Beloved Indie Blog 'The Hairpin' Became an AI Clickbait Farm". Wired. ISSN 1059-1028. Archived from the initial on April 14, 2024. Retrieved May 24, 2024.
^ Koebler, Jason (July 9, 2024). "A Beloved Tech Blog Is Now Publishing AI Articles Under the Names of Its Old Human Staff". 404 Media. Archived from the initial on July 12, 2024. Retrieved August 27, 2024.
^ Hollister, Sean (July 10, 2024). "Early Apple tech bloggers are shocked to discover their name and work have been AI-zombified". The Verge. Archived from the original on July 12, 2024. Retrieved August 27, 2024.
^ "AI slop is currently getting into Oregon's regional journalism". Oregon Public Broadcasting. December 9, 2024. Archived from the original on December 9, 2024. Retrieved December 10, 2024.
^ Knibbs, Kate (February 26, 2024). "How a Small Iowa Newspaper's Website Became an AI-Generated Clickbait Factory". Wired. ISSN 1059-1028. Archived from the original on February 26, 2024. Retrieved December 10, 2024.
^ Koebler, Jason; Cole, Samantha; Maiberg, Emanuel; Cox, Joseph (January 26, 2024). "We Need Your Email Address". 404 Media. Archived from the original on December 2, 2024. Retrieved December 10, 2024.
^ "Meet the Serbian Businessman/DJ Who Runs the Zombie AI Southwest Journal - Racket". Racket. February 16, 2024. Archived from the initial on November 13, 2024. Retrieved December 10, 2024.
^ Lima-Strong, Cristiano (January 11, 2024). "Senators alert AI could lead to 'destruction' of local news". Washington Post. ISSN 0190-8286. Archived from the initial on January 11, 2024. Retrieved May 24, 2024.
^ "OpenAI strikes $5 million-plus local news deal". Axios. July 18, 2023. Archived from the initial on July 19, 2023. Retrieved May 24, 2024.
^ Kelly, Heather (May 22, 2024). "Meta ignored news. Now the business's using it for AI content". Washington Post. ISSN 0190-8286. Archived from the initial on May 22, 2024. Retrieved May 24, 2024.
^ "How WIRED Will Use Generative AI Tools". Wired. Archived from the initial on December 30, 2023. Retrieved January 8, 2024.
^ Barrett, Amanda (November 15, 2018). "Standards around generative AI". Associated Press. Archived from the initial on September 23, 2023. Retrieved January 8, 2024.
^ Viner, Katharine; Bateson, Anna (June 16, 2023). "The Guardian's approach to generative AI". The Guardian. ISSN 0261-3077. Archived from the initial on January 3, 2024. Retrieved January 8, 2024.
^ Becker, K. B.; Simon, F. M.; Crum, C. (2023 ). "Policies in parallel? A comparative study of journalistic AI policies in 52 global news organisations". pp. 8-9. doi:10.31235/ osf.io/ c4af9.
^ Newman, Nic; Fletcher, Richard; Robertson, Craig T.; Arguedas, Amy Ross; Nielsen, Rasmus Fleis (June 2024). "Digital Report 2024" (PDF). Reuters Institute for the Study of Journalism.
#15 Test forum » Open-R1: a Totally Open Reproduction Of DeepSeek-R1 » 2025-02-01 07:08:29
- Darrin54C
- Replies: 0

Hey there! This article is an intro to the job, not a claim that we have actually replicated R1 yet. We're integrating in the open, so as quickly as we have evaluation numbers, we'll share them. You can follow our progress on Hugging Face and GitHub.
True, however it appears like there's nothing to be evaluated since today. I assume the supreme goal is to train a new thinking model and then use the same evaluation metrics as o1 and the DeepSeek-R1.
Well, there ought to be at least some peace of mind check and recognition to make sure the model was trained correctly.
Oh yes, if you are talking about the assessment variety of deepseek's design it's coming very soon!
As mentioned in the blog post there is no design called Open-R1 to test at all ... not yet anyway. This is a blog site detailing that Hugging face will take the R1 Deepseek design, work out how it was developed as detailed in the paper and from what they launched, and then replicate that procedure.
in fact this is quite much how science works ... A comes up with a plan, discovery or development and it is evaluated by B, C and D to see if it is reproduceable. Thats been the cornerstone of research now for a couple of centuries.
This blog site is not stating they have currently done so ... Its a blog site laying out an intent to start training a design like R1 and calling it Open-R1.
Also DeepSeek-R1 was only released recently, and even in their paper they outlined the compute hours required. While those are low calculate hours for a SOTA model this does not suggest you can train stated model in a week. I 'd personally like to be able to train a transformer model in a week, however we may need to wait a while for that level of compute technology.
So there are no benchmarks for a model that has not been built yet right? As laid out in the blog site, and once again in reply to your question.
However fear not, there is a GitHub Repo already and factors (hell I may join myself), some prelim work done, and a master plan. An excellent starting position.
n
@edbeeching
has actually assessed the launched designs currently
( src: https://x.com/edwardbeeching/status/188 … 136275742)
R1 just trained on o1 outputs, so jointly .../ s. This is what the brand-new AI czars are stating
Hi! This article is an introduction to the task, not a claim that we have actually replicated R1 yet. We will totally share the missing piece when we have them, you can anticipate the designs and datasets to be upload in this Hugging Face org and the code to be in this GitHub repo
That's nice and crucial to understand this incredible buzz that lacks technical understanding and explanation. Science is about recreation, and if they claim to be open, let them fullfill the open part.
Please do publish the training cost.
We will!
Excalidraw Hi n
@bojan2501
thanks, we will undoubtedly be striving to make sure this training dish can work for small language models on consumer hardware given that not everyone has a cluster of H100s at home:-RRB- The tool we used for the images was Excalidraw! https://excalidraw.com
looking forward to it! WTF are your talking about?
must be a joke
It's really cool to see how the entire open source neighborhood comes together!
Ops ...
5.5 M is number press reporter in the deepseekv3 tech report (simply the training, not the experiment afaik), for R1 difficult to approximate tbh however much less than 5.5 M imo
Historically, they have actually never ever launched code or datasets of their LLM training, so I would not expect this time to be various. If they would launch it that would be incredible of course!
Yes obviously!
So basically you're asking to replace existing censorship with another flavour of censorship?
The code for the designs are inside the model repositories, e.g. for V3: https://huggingface.co/deepseek-ai/DeepSeek-V3/blob/main/modeling_deepseek.py
Hello Team, I'm Ray Bernard, the author and creator of EQUATOR. My research study team will be dealing with a paper concentrated on reproducing certain parts of DeepSeek R1. Our goal is to replicate the cold start and offer your group with a dataset that consists of COT and other methods to support these efforts. We like to contribute our work to assist. Please let me know if you find this helpful. Best, Ray Bernard https://www.facebook.com/groups/1186310571520299/
Where is the assessment numbers? without it you can't call it recreation.
8 replies
True, however it looks like there's nothing to be examined since right now. I assume the supreme goal is to train a new thinking model and after that utilize the same evaluation metrics as o1 and the DeepSeek-R1.
That's rather fascinating, I was asking myself why the questions the author exposed here are not being asked by others? I think the work they have actually done is unforgettable but at the exact same time I wonder why they would not put these missing pieces on if they are supposed to be totally open.
Why even without reproduction and comprehension of the development they could impact a lot the marketplace in this method?
4 replies
Hi! This blog site post is an intro to the project, not a claim that we've reproduced R1 yet. We will totally share the missing out on piece when we have them, you can anticipate the models and datasets to be upload in this Hugging Face org and the code to be in this GitHub repo
Interesting read, and it is good that we see more effort into this direction: more optimization and less brute force.
Also wonder what tool did the author usage for developing step diagram.
2 replies
Excalidraw I'm so glad that initiative like this currently exist, I'm gon na attempt to contribute:-RRB- 1 reply
looking forward to it! So racist articel
2 replies
WTF are your talking about?
Awesome to have this open reproduction began!
For Step # 1 check out https://github.com/open-thoughts/open-thoughts!
https://x.com/ryanmart3n/status/1884284101265612856
Let's do this thing!
1 reply
It's really cool to see how the entire open source community comes together!
Does anybody understand the actual training cost of r1? I can't discover it in the paper or the announcement post. Is the 6M expense reported by media just the number drawn from v3's training cost?
2 replies
Ops ...
Has anyone asked the DeepSeek group to release their training information and code, or a minimum of share them privately with an independent duplication project like this? Have they declined such a request?
A faithful duplication depends upon using the very same dataset and hyperparameters. Otherwise, any significant disparities with the published standards would be hard to pin down-whether due to training information differences or the duplication method itself.
1 reply
Historically, they have actually never launched code or datasets of their LLM training, so I wouldn't expect this time to be different. If they would launch it that would be incredible obviously!
In the meantime we have to make finest guess quotes and see if we can get there ourselves.
You supply excellent replication process of Deepseek thinking training. I will attempt something comparable to it.
This is really great information, can we tweak with particular use case when code is launched?
1 reply
Yes naturally!
Please think about removing biased, polluted or unaligned training information and make an effort to get rid of copyrighted works from the crawl from intake. This will make the model more functional. If you recycled anthropic curation checks, this may likewise assist, remove obviouslybiased information will likely include a lot of worth. We do not desire another tainted, unaligned open source model, right? And no corporate would ever utilize deepseek or a model that reuses it, right?
We value your work for the advantage of mankind, we hope.
Miike C from NJ
1 reply
So generally you're asking to change existing censorship with another flavour of censorship?
Can't wait! Hopefully the model will be uncensored but whatever you can do is alright! Love seeing open source structure itself up. I'm not smart enough to really assist but I can contribute moral assistance lol
Hello guys, I am even simply searching for code for DeepSeek-V2, in order to fully comprehend multi-head hidden attention. You do not seem to have code in Hugging Face even for that. Or am I missing something? Don't see anything in src/transformers/models. MLA is not properly described in their paper, so it would be necessary to have code for this.
#16 Test forum » DeepSeek R-1 Model Overview and how it Ranks Versus OpenAI's O1 » 2025-02-01 06:42:03
- Darrin54C
- Replies: 0
DeepSeek is a Chinese AI company "dedicated to making AGI a reality" and open-sourcing all its models. They began in 2023, however have actually been making waves over the previous month or so, and specifically this previous week with the release of their two most current reasoning designs: DeepSeek-R1-Zero and the more innovative DeepSeek-R1, likewise referred to as DeepSeek Reasoner.
They have actually launched not just the models however also the code and examination triggers for public usage, together with an in-depth paper describing their approach.
Aside from producing 2 extremely performant models that are on par with OpenAI's o1 design, the paper has a lot of important details around support learning, chain of thought reasoning, prompt engineering with thinking models, and more.
We'll start by focusing on the training process of DeepSeek-R1-Zero, which distinctively relied exclusively on support knowing, rather of traditional monitored knowing. We'll then proceed to DeepSeek-R1, how it's thinking works, and some timely engineering finest practices for reasoning models.
Hey everyone, Dan here, co-founder of PromptHub. Today, we're diving into DeepSeek's newest model release and comparing it with OpenAI's reasoning designs, particularly the A1 and A1 Mini models. We'll explore their training procedure, thinking capabilities, and some essential insights into prompt engineering for thinking designs.
DeepSeek is a Chinese-based AI business dedicated to open-source advancement. Their current release, the R1 thinking model, is groundbreaking due to its open-source nature and ingenious training approaches. This consists of open access to the models, prompts, and research study papers.
Released on January 20th, DeepSeek's R1 achieved excellent efficiency on numerous criteria, measuring up to OpenAI's A1 models. Notably, they likewise introduced a precursor model, R10, which works as the foundation for R1.
Training Process: R10 to R1
R10: This model was trained exclusively using support learning without supervised fine-tuning, making it the very first open-source design to accomplish high efficiency through this method. Training involved:
- Rewarding proper responses in deterministic jobs (e.g., math issues).
- Encouraging structured reasoning outputs using templates with "" and "" tags
Through thousands of iterations, R10 established longer thinking chains, self-verification, and even reflective habits. For example, throughout training, the design demonstrated "aha" minutes and self-correction behaviors, which are uncommon in conventional LLMs.
R1: Building on R10, R1 added numerous improvements:
- Curated datasets with long Chain of Thought examples.
- Incorporation of R10-generated thinking chains.
- Human preference positioning for polished reactions.
- Distillation into smaller models (LLaMA 3.1 and 3.3 at different sizes).
Performance Benchmarks
DeepSeek's R1 design performs on par with OpenAI's A1 designs throughout numerous reasoning criteria:
Reasoning and Math Tasks: R1 competitors or surpasses A1 designs in accuracy and depth of thinking.
Coding Tasks: A1 designs normally perform better in LiveCode Bench and CodeForces jobs.
Simple QA: R1 typically outmatches A1 in structured QA tasks (e.g., 47% accuracy vs. 30%).
One significant finding is that longer reasoning chains generally enhance efficiency. This lines up with insights from Microsoft's Med-Prompt structure and OpenAI's observations on test-time calculate and thinking depth.
Challenges and Observations
Despite its strengths, R1 has some limitations:
- Mixing English and Chinese actions due to an absence of supervised fine-tuning.
- Less refined responses compared to chat models like OpenAI's GPT.
These concerns were addressed during R1's improvement process, consisting of monitored fine-tuning and human feedback.
Prompt Engineering Insights
A fascinating takeaway from DeepSeek's research study is how few-shot triggering abject R1's efficiency compared to zero-shot or succinct tailored prompts. This aligns with findings from the Med-Prompt paper and OpenAI's suggestions to limit context in reasoning designs. Overcomplicating the input can overwhelm the model and decrease precision.
DeepSeek's R1 is a considerable action forward for open-source reasoning designs, showing capabilities that measure up to OpenAI's A1. It's an interesting time to try out these models and their chat user interface, which is free to utilize.
If you have concerns or desire to discover more, take a look at the resources connected below. See you next time!
Training DeepSeek-R1-Zero: A support learning-only method
DeepSeek-R1-Zero stands apart from a lot of other modern models because it was trained utilizing just reinforcement knowing (RL), no monitored fine-tuning (SFT). This challenges the existing standard technique and opens new opportunities to train thinking designs with less human intervention and effort.
DeepSeek-R1-Zero is the first open-source model to verify that innovative thinking capabilities can be established purely through RL.
Without pre-labeled datasets, the design finds out through trial and mistake, improving its behavior, parameters, and weights based solely on feedback from the options it produces.
DeepSeek-R1-Zero is the base design for DeepSeek-R1.
The RL process for DeepSeek-R1-Zero
The training procedure for DeepSeek-R1-Zero involved presenting the model with numerous thinking jobs, ranging from math issues to abstract reasoning challenges. The design produced outputs and was assessed based upon its efficiency.
DeepSeek-R1-Zero received feedback through a reward system that assisted guide its knowing process:
Accuracy benefits: Evaluates whether the output is proper. Used for when there are deterministic results (math issues).
Format benefits: Encouraged the design to structure its reasoning within and tags.
Training timely template
To train DeepSeek-R1-Zero to produce structured chain of idea series, the scientists used the following timely training template, changing timely with the thinking concern. You can access it in PromptHub here.
This design template prompted the model to explicitly outline its idea procedure within tags before delivering the last answer in tags.
The power of RL in reasoning
With this training procedure DeepSeek-R1-Zero started to produce advanced thinking chains.
Through countless training actions, DeepSeek-R1-Zero progressed to fix increasingly complex problems. It found out to:
- Generate long reasoning chains that enabled deeper and more structured analytical
- Perform self-verification to cross-check its own answers (more on this later).
- Correct its own errors, showcasing emerging self-reflective behaviors.
DeepSeek R1-Zero performance
While DeepSeek-R1-Zero is mostly a precursor to DeepSeek-R1, it still attained high efficiency on numerous standards. Let's dive into some of the experiments ran.
Accuracy improvements throughout training
- Pass@1 precision started at 15.6% and by the end of the training it enhanced to 71.0%, equivalent to OpenAI's o1-0912 model.
- The red strong line represents performance with bulk ballot (comparable to ensembling and self-consistency techniques), which increased precision even more to 86.7%, going beyond o1-0912.
Next we'll look at a table comparing DeepSeek-R1-Zero's efficiency throughout numerous reasoning datasets against OpenAI's thinking designs.
AIME 2024: 71.0% Pass@1, somewhat listed below o1-0912 however above o1-mini. 86.7% cons@64, beating both o1 and o1-mini.
MATH-500: Achieved 95.9%, beating both o1-0912 and o1-mini.
GPQA Diamond: Outperformed o1-mini with a rating of 73.3%.
- Performed much even worse on coding tasks (CodeForces and LiveCode Bench).
Next we'll look at how the action length increased throughout the RL training process.
This chart shows the length of reactions from the design as the training process advances. Each "action" represents one cycle of the design's knowing process, where feedback is supplied based on the output's performance, evaluated using the prompt design template talked about earlier.
For each question (corresponding to one action), 16 actions were sampled, and the typical precision was computed to guarantee steady evaluation.
As training advances, the design generates longer reasoning chains, allowing it to fix significantly complicated reasoning jobs by leveraging more test-time compute.
While longer chains don't always guarantee much better results, they generally associate with enhanced performance-a pattern likewise observed in the MEDPROMPT paper (read more about it here) and in the original o1 paper from OpenAI.
Aha moment and self-verification
Among the coolest elements of DeepSeek-R1-Zero's advancement (which also applies to the flagship R-1 design) is simply how good the model ended up being at reasoning. There were advanced thinking behaviors that were not clearly programmed but occurred through its reinforcement learning procedure.
Over thousands of training actions, the model began to self-correct, review problematic reasoning, and verify its own solutions-all within its chain of thought
An example of this noted in the paper, described as a the "Aha moment" is below in red text.
In this instance, the model literally stated, "That's an aha moment." Through DeepSeek's chat feature (their variation of ChatGPT) this type of reasoning typically emerges with expressions like "Wait a minute" or "Wait, but ... ,"
Limitations and difficulties in DeepSeek-R1-Zero
While DeepSeek-R1-Zero was able to carry out at a high level, there were some disadvantages with the model.
Language mixing and coherence issues: The model occasionally produced responses that combined languages (Chinese and English).
Reinforcement learning trade-offs: The absence of supervised fine-tuning (SFT) meant that the model did not have the refinement needed for fully polished, human-aligned outputs.
DeepSeek-R1 was developed to attend to these concerns!
What is DeepSeek R1
DeepSeek-R1 is an open-source reasoning model from the Chinese AI lab DeepSeek. It constructs on DeepSeek-R1-Zero, which was trained totally with reinforcement knowing. Unlike its predecessor, DeepSeek-R1 integrates monitored fine-tuning, making it more refined. Notably, it exceeds OpenAI's o1 model on a number of benchmarks-more on that later on.
What are the primary distinctions between DeepSeek-R1 and DeepSeek-R1-Zero?
DeepSeek-R1 constructs on the foundation of DeepSeek-R1-Zero, which works as the base design. The two vary in their training techniques and overall performance.
1. Training method
DeepSeek-R1-Zero: Trained entirely with support knowing (RL) and no supervised fine-tuning (SFT).
DeepSeek-R1: Uses a multi-stage training pipeline that includes monitored fine-tuning (SFT) first, followed by the exact same reinforcement finding out procedure that DeepSeek-R1-Zero damp through. SFT assists enhance coherence and readability.
2. Readability & Coherence
DeepSeek-R1-Zero: Had problem with language mixing (English and Chinese) and readability concerns. Its reasoning was strong, however its outputs were less polished.
DeepSeek-R1: Addressed these concerns with cold-start fine-tuning, making responses clearer and more structured.
3. Performance
DeepSeek-R1-Zero: Still a really strong thinking model, sometimes beating OpenAI's o1, however fell the language blending problems minimized usability considerably.
DeepSeek-R1: Outperforms R1-Zero and OpenAI's o1 on a lot of thinking criteria, and the actions are a lot more polished.
Simply put, DeepSeek-R1-Zero was a proof of concept, while DeepSeek-R1 is the fully enhanced variation.
How DeepSeek-R1 was trained
To deal with the readability and coherence concerns of R1-Zero, the scientists included a cold-start fine-tuning phase and a multi-stage training pipeline when developing DeepSeek-R1:
Cold-Start Fine-Tuning:
- Researchers prepared a premium dataset of long chains of idea examples for preliminary supervised fine-tuning (SFT). This data was collected using:- Few-shot prompting with detailed CoT examples.
- Post-processed outputs from DeepSeek-R1-Zero, refined by human annotators.

Reinforcement Learning:
DeepSeek-R1 underwent the exact same RL process as DeepSeek-R1-Zero to refine its thinking capabilities further.
Human Preference Alignment:
- A secondary RL phase improved the model's helpfulness and harmlessness, ensuring better alignment with user requirements.
Distillation to Smaller Models:
- DeepSeek-R1's reasoning abilities were distilled into smaller sized, effective models like Qwen and Llama-3.1 -8 B, and Llama-3.3 -70 B-Instruct.
DeepSeek R-1 standard efficiency
The scientists tested DeepSeek R-1 throughout a variety of criteria and versus top designs: o1, GPT-4o, and Claude 3.5 Sonnet, o1-mini.
The standards were broken down into numerous classifications, revealed listed below in the table: English, Code, Math, and Chinese.
Setup
The following parameters were used throughout all designs:
Maximum generation length: 32,768 tokens.
Sampling configuration:- Temperature: 0.6.
- Top-p worth: 0.95.
- DeepSeek R1 outshined o1, Claude 3.5 Sonnet and other designs in the majority of thinking criteria.
o1 was the best-performing model in four out of the five coding-related criteria.
- DeepSeek performed well on imaginative and long-context task task, like AlpacaEval 2.0 and ArenaHard, outperforming all other models.

Prompt Engineering with reasoning designs
My preferred part of the post was the scientists' observation about DeepSeek-R1's level of sensitivity to prompts:
This is another datapoint that aligns with insights from our Prompt Engineering with Reasoning Models Guide, which referrals Microsoft's research on their MedPrompt framework. In their research study with OpenAI's o1-preview model, they discovered that frustrating reasoning designs with few-shot context broken down performance-a sharp contrast to non-reasoning designs.
The key takeaway? Zero-shot prompting with clear and succinct guidelines seem to be best when using reasoning designs.
#17 Test forum » GitHub - Deepseek-ai/DeepSeek-V3 » 2025-02-01 06:19:59
- Darrin54C
- Replies: 0
We provide DeepSeek-V3, a strong Mixture-of-Experts (MoE) language design with 671B total criteria with 37B triggered for each token. To accomplish efficient reasoning and economical training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly confirmed in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free technique for load balancing and sets a multi-token prediction training goal for more powerful performance. We pre-train DeepSeek-V3 on 14.8 trillion varied and premium tokens, followed by Supervised Fine-Tuning and Reinforcement Learning phases to totally harness its abilities. Comprehensive examinations expose that DeepSeek-V3 outshines other open-source designs and attains performance equivalent to leading closed-source designs. Despite its exceptional efficiency, DeepSeek-V3 needs just 2.788 M H800 GPU hours for its complete training. In addition, its training procedure is extremely stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or carry out any rollbacks.
2. Model Summary
Architecture: Innovative Load Balancing Strategy and Training Objective
- On top of the efficient architecture of DeepSeek-V2, we leader an auxiliary-loss-free method for load balancing, which minimizes the efficiency degradation that emerges from encouraging load balancing.
- We investigate a Multi-Token Prediction (MTP) objective and prove it useful to design performance. It can also be used for speculative decoding for inference velocity.
Pre-Training: Towards Ultimate Training Efficiency
- We design an FP8 combined accuracy training framework and, for the very first time, validate the feasibility and effectiveness of FP8 training on an incredibly large-scale model.
- Through co-design of algorithms, structures, and hardware, we get rid of the interaction traffic jam in cross-node MoE training, nearly attaining full computation-communication overlap.
This significantly enhances our training efficiency and lowers the training expenses, enabling us to further scale up the design size without additional overhead.
- At an economical expense of just 2.664 M H800 GPU hours, we complete the pre-training of DeepSeek-V3 on 14.8 T tokens, producing the currently greatest open-source base design. The subsequent training phases after pre-training need just 0.1 M GPU hours.
Post-Training: Knowledge Distillation from DeepSeek-R1
- We present an innovative approach to boil down thinking abilities from the long-Chain-of-Thought (CoT) model, particularly from among the DeepSeek R1 series models, into basic LLMs, especially DeepSeek-V3. Our pipeline elegantly includes the verification and reflection patterns of R1 into DeepSeek-V3 and especially improves its thinking efficiency. Meanwhile, we likewise keep a control over the output design and length of DeepSeek-V3.
3. Model Downloads
The total size of DeepSeek-V3 models on Hugging Face is 685B, that includes 671B of the Main Model weights and 14B of the Multi-Token Prediction (MTP) Module weights. **
To make sure optimal efficiency and versatility, we have partnered with open-source neighborhoods and hardware vendors to supply numerous methods to run the design locally. For step-by-step guidance, have a look at Section 6: How_to Run_Locally.
For developers aiming to dive much deeper, we suggest exploring README_WEIGHTS. md for information on the Main Model weights and the Multi-Token Prediction (MTP) Modules. Please note that MTP support is presently under active advancement within the community, and we invite your contributions and feedback.
4. Evaluation Results
Base Model
Standard Benchmarks
Best results are shown in bold. Scores with a space not surpassing 0.3 are thought about to be at the very same level. DeepSeek-V3 attains the best efficiency on the majority of standards, specifically on math and code tasks. For more assessment information, please examine our paper.
Context Window
Evaluation results on the Needle In A Haystack (NIAH) tests. DeepSeek-V3 carries out well across all context window lengths as much as 128K.
Chat Model
Standard Benchmarks (Models bigger than 67B)
All models are assessed in a configuration that restricts the output length to 8K. Benchmarks including less than 1000 samples are evaluated multiple times using varying temperature settings to derive robust outcomes. DeepSeek-V3 stands as the best-performing open-source model, and likewise shows competitive performance against frontier closed-source models.
Open Ended Generation Evaluation
English open-ended conversation evaluations. For AlpacaEval 2.0, we utilize the length-controlled win rate as the metric.
5. Chat Website & API Platform
You can talk with DeepSeek-V3 on DeepSeek's official website: chat.deepseek.com
We also supply OpenAI-Compatible API at DeepSeek Platform: platform.deepseek.com
6. How to Run Locally
DeepSeek-V3 can be deployed in your area utilizing the following hardware and open-source community software application:
DeepSeek-Infer Demo: We provide a simple and light-weight demonstration for FP8 and BF16 reasoning.
SGLang: Fully support the DeepSeek-V3 design in both BF16 and FP8 inference modes, with Multi-Token Prediction coming quickly.
LMDeploy: Enables efficient FP8 and BF16 reasoning for local and cloud implementation.
TensorRT-LLM: Currently supports BF16 reasoning and INT4/8 quantization, with FP8 assistance coming quickly.
vLLM: Support DeepSeek-V3 model with FP8 and BF16 modes for tensor parallelism and pipeline parallelism.
AMD GPU: Enables running the DeepSeek-V3 design on AMD GPUs via SGLang in both BF16 and FP8 modes.
Huawei Ascend NPU: Supports running DeepSeek-V3 on Huawei Ascend gadgets.
Since FP8 training is natively adopted in our structure, we only provide FP8 weights. If you need BF16 weights for experimentation, you can use the supplied conversion script to carry out the change.
Here is an example of converting FP8 weights to BF16:
Hugging Face's Transformers has not been straight supported yet. **
6.1 Inference with DeepSeek-Infer Demo (example just)
System Requirements
Note
Linux with Python 3.10 only. Mac and Windows are not supported.
Dependencies:![]()
Model Weights & Demo Code Preparation
First, clone our DeepSeek-V3 GitHub repository:
Navigate to the reasoning folder and set up dependences listed in requirements.txt. Easiest way is to use a plan supervisor like conda or uv to produce a new virtual environment and install the dependencies.
Download the model weights from Hugging Face, and put them into/ path/to/DeepSeek-V 3 folder.
Model Weights Conversion
Convert Hugging Face design weights to a particular format:
Run
Then you can chat with DeepSeek-V3:
Or batch inference on an offered file:
6.2 Inference with SGLang (advised)
SGLang currently supports MLA optimizations, DP Attention, FP8 (W8A8), FP8 KV Cache, and Torch Compile, delivering advanced latency and throughput efficiency among open-source frameworks.
Notably, SGLang v0.4.1 completely supports running DeepSeek-V3 on both NVIDIA and AMD GPUs, making it an extremely versatile and robust option.
SGLang also supports multi-node tensor parallelism, allowing you to run this model on multiple network-connected makers.
Multi-Token Prediction (MTP) remains in development, and development can be tracked in the optimization strategy.
Here are the launch instructions from the SGLang team: https://github.com/sgl-project/sglang/t … eepseek_v3
6.3 Inference with LMDeploy (advised)
LMDeploy, a versatile and high-performance inference and serving structure tailored for big language models, now supports DeepSeek-V3. It offers both offline pipeline processing and online release abilities, seamlessly integrating with PyTorch-based workflows.
For thorough step-by-step guidelines on running DeepSeek-V3 with LMDeploy, please refer to here: InternLM/lmdeploy # 2960
6.4 Inference with TRT-LLM (advised)
TensorRT-LLM now supports the DeepSeek-V3 design, offering precision alternatives such as BF16 and INT4/INT8 weight-only. Support for FP8 is presently in development and will be launched quickly. You can access the custom-made branch of TRTLLM specifically for DeepSeek-V3 support through the following link to experience the new features straight: https://github.com/NVIDIA/TensorRT-LLM/ … eepseek_v3.
6.5 Inference with vLLM (suggested)
vLLM v0.6.6 supports DeepSeek-V3 inference for FP8 and BF16 modes on both NVIDIA and AMD GPUs. Aside from standard techniques, vLLM offers pipeline parallelism permitting you to run this model on several devices linked by networks. For detailed assistance, please refer to the vLLM instructions. Please do not hesitate to follow the improvement strategy as well.
6.6 Recommended Inference Functionality with AMD GPUs
In cooperation with the AMD team, we have actually attained Day-One assistance for AMD GPUs using SGLang, with full compatibility for both FP8 and BF16 precision. For comprehensive assistance, please refer to the SGLang instructions.
6.7 Recommended Inference Functionality with Huawei Ascend NPUs
The MindIE structure from the Huawei Ascend community has actually effectively adjusted the BF16 version of DeepSeek-V3. For detailed assistance on Ascend NPUs, please follow the directions here.
7. License
This code repository is accredited under the MIT License. Making use of DeepSeek-V3 Base/Chat designs undergoes the Model License. DeepSeek-V3 series (including Base and Chat) supports industrial use.
#18 Test forum » Chinese Chatbot Brought down the uS Stock Market » 2025-02-01 06:18:44
- Darrin54C
- Replies: 0
The Chinese chatbot DeepSeek demolished the US stock exchange, bringing down the capitalization of American companies by a trillion dollars. This is reported by the world media.
This is reported by the world media.
Chinese AI DeepSeek overtook ChatGPT and reduced worldwide stock markets, composes, in particular, Reuters.
The look on the market of the Chinese chatbot DeepSeek-R1 following the results of one exchange day, on January 27, cost the American microchip producer Nvidia practically $ 600 billion in market price, the BBC reports.
According to information published in a number of other media outlets, the remaining innovation giants related to the development of artificial intelligence have lost many 10s of billions of dollars more. In particular, Broadcom lost 17.4%, or about $ 200 billion. Microsoft's stock rate fell by 2.14% (about $ 70 billion) throughout the day, and the shares of Google's owner, Alphabet, decreased by 4% ($95 billion).
Microsoft's stock rate fell by 2.14% (about $ 70 billion) throughout the day, and the shares of Google's owner, Alphabet, decreased by 4% ($95 billion).
The total index of American technology business Nasdaq-100 fell by practically 3%.
American companies have invested and strategy to invest hundreds of billions of dollars in the development of synthetic intelligence systems. While the Chinese business DeepSeek it cost $ 5.6 million.
While the Chinese business DeepSeek it cost $ 5.6 million.
#19 Test forum » DeepSeek R-1 Model Overview and how it Ranks against OpenAI's O1 » 2025-02-01 06:11:58
- Darrin54C
- Replies: 0
DeepSeek is a Chinese AI business "dedicated to making AGI a reality" and open-sourcing all its designs. They started in 2023, however have been making waves over the past month or two, and especially this past week with the release of their 2 latest thinking designs: DeepSeek-R1-Zero and the advanced DeepSeek-R1, also understood as DeepSeek Reasoner.
They've launched not just the models but also the code and examination prompts for public use, together with a comprehensive paper detailing their technique.
Aside from developing 2 highly performant models that are on par with OpenAI's o1 model, the paper has a great deal of valuable details around support learning, chain of thought thinking, timely engineering with thinking models, and more.
We'll start by concentrating on the training procedure of DeepSeek-R1-Zero, which distinctively relied solely on support knowing, instead of conventional supervised learning. We'll then move on to DeepSeek-R1, how it's thinking works, and some prompt engineering best practices for thinking models.
Hey everyone, Dan here, co-founder of PromptHub. Today, we're diving into DeepSeek's most current model release and comparing it with OpenAI's reasoning models, particularly the A1 and A1 Mini models. We'll explore their training procedure, reasoning capabilities, and some essential insights into timely engineering for thinking models.
DeepSeek is a Chinese-based AI company dedicated to open-source advancement. Their current release, the R1 thinking model, is groundbreaking due to its open-source nature and ingenious training techniques. This consists of open access to the models, prompts, and research documents.
Released on January 20th, DeepSeek's R1 attained outstanding performance on numerous standards, equaling OpenAI's A1 designs. Notably, they also launched a precursor model, R10, which works as the structure for R1.
Training Process: R10 to R1
R10: This model was trained specifically using support learning without supervised fine-tuning, making it the first open-source design to accomplish high efficiency through this technique. Training involved:
- Rewarding right responses in deterministic tasks (e.g., math issues).
- Encouraging structured reasoning outputs using design templates with "" and "" tags
Through countless versions, R10 developed longer reasoning chains, self-verification, and even reflective behaviors. For instance, throughout training, the design demonstrated "aha" moments and self-correction habits, which are rare in standard LLMs.
R1: Building on R10, R1 added numerous enhancements:
- Curated datasets with long Chain of Thought examples.
- Incorporation of R10-generated reasoning chains.
- Human choice positioning for refined responses.
- Distillation into smaller sized designs (LLaMA 3.1 and 3.3 at different sizes).
Performance Benchmarks
DeepSeek's R1 design carries out on par with OpenAI's A1 models throughout lots of reasoning criteria:
Reasoning and Math Tasks: R1 competitors or outshines A1 designs in accuracy and depth of thinking.
Coding Tasks: A1 designs typically perform much better in LiveCode Bench and CodeForces tasks.
Simple QA: R1 often outpaces A1 in structured QA tasks (e.g., 47% precision vs. 30%).
One significant finding is that longer thinking chains generally enhance efficiency. This lines up with insights from Microsoft's Med-Prompt framework and OpenAI's observations on test-time calculate and thinking depth.
Challenges and Observations
Despite its strengths, R1 has some restrictions:
- Mixing English and Chinese reactions due to a lack of supervised fine-tuning.
- Less refined actions compared to chat models like OpenAI's GPT.
These issues were resolved during R1's improvement process, including supervised fine-tuning and human feedback.
Prompt Engineering Insights
A remarkable takeaway from DeepSeek's research study is how few-shot triggering degraded R1's performance compared to zero-shot or succinct customized prompts. This lines up with findings from the Med-Prompt paper and OpenAI's suggestions to restrict context in thinking designs. Overcomplicating the input can overwhelm the design and reduce precision.
DeepSeek's R1 is a considerable advance for open-source reasoning designs, demonstrating abilities that equal OpenAI's A1. It's an amazing time to try out these models and their chat interface, which is complimentary to utilize.
If you have concerns or wish to discover more, have a look at the resources linked below. See you next time!
Training DeepSeek-R1-Zero: A support learning-only approach
DeepSeek-R1-Zero stands out from most other advanced designs due to the fact that it was trained utilizing only support learning (RL), no monitored fine-tuning (SFT). This challenges the present conventional technique and opens up brand-new opportunities to train thinking models with less human intervention and effort.
DeepSeek-R1-Zero is the very first open-source model to validate that innovative reasoning abilities can be developed simply through RL.
Without pre-labeled datasets, the design finds out through experimentation, improving its habits, specifications, and weights based entirely on feedback from the services it generates.
DeepSeek-R1-Zero is the base model for DeepSeek-R1.
The RL procedure for DeepSeek-R1-Zero
The training procedure for DeepSeek-R1-Zero involved providing the design with different reasoning jobs, ranging from math issues to abstract reasoning obstacles. The design created outputs and was assessed based on its efficiency.
DeepSeek-R1-Zero received feedback through a benefit system that helped assist its learning procedure:
Accuracy rewards: Evaluates whether the output is right. Used for when there are deterministic outcomes (math issues).
Format benefits: Encouraged the design to structure its reasoning within and tags.
Training prompt template
To train DeepSeek-R1-Zero to create structured chain of idea sequences, the researchers used the following prompt training template, replacing timely with the reasoning concern. You can access it in PromptHub here.
This template triggered the model to clearly describe its idea procedure within tags before delivering the last answer in tags.
The power of RL in reasoning
With this training procedure DeepSeek-R1-Zero started to produce sophisticated reasoning chains.
Through thousands of training actions, DeepSeek-R1-Zero developed to fix increasingly intricate problems. It found out to:
- Generate long thinking chains that allowed deeper and more structured problem-solving
- Perform self-verification to cross-check its own answers (more on this later).
- Correct its own mistakes, showcasing emergent self-reflective behaviors.
DeepSeek R1-Zero performance
While DeepSeek-R1-Zero is primarily a precursor to DeepSeek-R1, it still attained high performance on several benchmarks. Let's dive into a few of the experiments ran.
Accuracy improvements throughout training
- Pass@1 accuracy started at 15.6% and by the end of the training it improved to 71.0%, similar to OpenAI's o1-0912 design.
- The red solid line represents efficiency with bulk ballot (comparable to ensembling and self-consistency strategies), which increased precision even more to 86.7%, exceeding o1-0912.
Next we'll take a look at a table comparing DeepSeek-R1-Zero's efficiency throughout numerous reasoning datasets versus OpenAI's reasoning models.
AIME 2024: 71.0% Pass@1, slightly listed below o1-0912 however above o1-mini. 86.7% cons@64, beating both o1 and o1-mini.
MATH-500: Achieved 95.9%, beating both o1-0912 and o1-mini.
GPQA Diamond: Outperformed o1-mini with a rating of 73.3%.
- Performed much even worse on coding tasks (CodeForces and LiveCode Bench).
Next we'll take a look at how the action length increased throughout the RL training process.
This graph shows the length of actions from the model as the training procedure advances. Each "step" represents one cycle of the design's knowing procedure, where feedback is supplied based upon the output's efficiency, examined utilizing the timely template gone over previously.
For each question (corresponding to one step), 16 actions were sampled, and the typical accuracy was computed to make sure stable assessment.
As training progresses, the design creates longer thinking chains, permitting it to solve progressively intricate reasoning jobs by leveraging more test-time calculate.
While longer chains do not constantly ensure much better results, they generally correlate with enhanced performance-a pattern also observed in the MEDPROMPT paper (find out more about it here) and in the initial o1 paper from OpenAI.
Aha minute and self-verification
One of the coolest elements of DeepSeek-R1-Zero's development (which likewise uses to the flagship R-1 design) is simply how good the design ended up being at thinking. There were sophisticated thinking habits that were not clearly configured however arose through its reinforcement learning process.
Over thousands of training steps, the design began to self-correct, reassess problematic reasoning, and verify its own solutions-all within its chain of idea
An example of this noted in the paper, described as a the "Aha minute" is below in red text.
In this instance, the model literally stated, "That's an aha moment." Through DeepSeek's chat function (their variation of ChatGPT) this kind of reasoning normally emerges with phrases like "Wait a minute" or "Wait, but ... ,"
Limitations and difficulties in DeepSeek-R1-Zero
While DeepSeek-R1-Zero was able to perform at a high level, there were some disadvantages with the design.
Language mixing and coherence issues: The design sometimes produced responses that combined languages (Chinese and English).
Reinforcement knowing trade-offs: The absence of monitored fine-tuning (SFT) suggested that the model lacked the improvement needed for totally polished, human-aligned outputs.
DeepSeek-R1 was established to deal with these issues!
What is DeepSeek R1
DeepSeek-R1 is an open-source reasoning design from the Chinese AI lab DeepSeek. It develops on DeepSeek-R1-Zero, which was trained entirely with reinforcement learning. Unlike its predecessor, DeepSeek-R1 incorporates monitored fine-tuning, making it more fine-tuned. Notably, it exceeds OpenAI's o1 model on numerous benchmarks-more on that later.
What are the primary distinctions in between DeepSeek-R1 and DeepSeek-R1-Zero?
DeepSeek-R1 develops on the structure of DeepSeek-R1-Zero, which serves as the base design. The 2 vary in their training techniques and general efficiency.
1. Training method
DeepSeek-R1-Zero: Trained totally with support knowing (RL) and no supervised fine-tuning (SFT).
DeepSeek-R1: Uses a multi-stage training pipeline that consists of supervised fine-tuning (SFT) initially, followed by the same reinforcement discovering procedure that DeepSeek-R1-Zero wet through. SFT assists improve coherence and readability.
2. Readability & Coherence
DeepSeek-R1-Zero: Struggled with language mixing (English and Chinese) and readability issues. Its thinking was strong, but its outputs were less polished.
DeepSeek-R1: Addressed these concerns with cold-start fine-tuning, making responses clearer and more structured.
3. Performance
DeepSeek-R1-Zero: Still a very strong reasoning design, sometimes beating OpenAI's o1, however fell the language mixing concerns decreased functionality significantly.
DeepSeek-R1: Outperforms R1-Zero and OpenAI's o1 on a lot of thinking criteria, and the reactions are far more polished.
Simply put, DeepSeek-R1-Zero was a proof of idea, while DeepSeek-R1 is the totally enhanced version.
How DeepSeek-R1 was trained
To deal with the readability and coherence problems of R1-Zero, the researchers integrated a cold-start fine-tuning stage and a multi-stage training pipeline when building DeepSeek-R1:
Cold-Start Fine-Tuning:
- Researchers prepared a high-quality dataset of long chains of idea examples for preliminary monitored fine-tuning (SFT). This data was collected utilizing:- Few-shot triggering with detailed CoT examples.
- Post-processed outputs from DeepSeek-R1-Zero, fine-tuned by human annotators.
Reinforcement Learning:
DeepSeek-R1 went through the same RL procedure as DeepSeek-R1-Zero to refine its thinking abilities even more.
Human Preference Alignment:
- A secondary RL phase enhanced the design's helpfulness and harmlessness, making sure much better positioning with user needs.
Distillation to Smaller Models:
- DeepSeek-R1's thinking abilities were distilled into smaller, efficient designs like Qwen and Llama-3.1 -8 B, and Llama-3.3 -70 B-Instruct.
DeepSeek R-1 criteria performance
The researchers tested DeepSeek R-1 across a range of criteria and versus top models: o1, GPT-4o, and Claude 3.5 Sonnet, o1-mini.
The criteria were broken down into numerous classifications, shown listed below in the table: English, Code, Math, and Chinese.
Setup
The following specifications were used throughout all designs:
Maximum generation length: 32,768 tokens.
Sampling configuration:- Temperature: 0.6.
- Top-p worth: 0.95.
- DeepSeek R1 outshined o1, Claude 3.5 Sonnet and other models in the majority of thinking standards.
o1 was the best-performing design in 4 out of the 5 coding-related criteria.
- DeepSeek carried out well on innovative and long-context task task, like AlpacaEval 2.0 and ArenaHard, exceeding all other models.
Prompt Engineering with reasoning models
My preferred part of the post was the scientists' observation about DeepSeek-R1's sensitivity to triggers:
This is another datapoint that aligns with insights from our Prompt Engineering with Reasoning Models Guide, which references Microsoft's research on their MedPrompt framework. In their study with OpenAI's o1-preview model, they found that frustrating reasoning designs with few-shot context degraded performance-a sharp contrast to non-reasoning models.
The key takeaway? Zero-shot prompting with clear and concise directions appear to be best when using reasoning models.
#20 Test forum » Explained: Generative AI's Environmental Impact » 2025-02-01 05:35:25
- Darrin54C
- Replies: 0
In a two-part series, MIT News explores the environmental implications of generative AI. In this article, we look at why this innovation is so resource-intensive. A 2nd piece will examine what specialists are doing to decrease genAI's carbon footprint and other effects.
The excitement surrounding prospective benefits of generative AI, from enhancing worker productivity to advancing clinical research study, is hard to ignore. While the explosive development of this brand-new technology has actually allowed quick deployment of powerful models in numerous markets, the environmental repercussions of this generative AI "gold rush" stay tough to pin down, not to mention mitigate.
The computational power needed to train generative AI designs that typically have billions of parameters, such as OpenAI's GPT-4, can demand a shocking amount of electricity, which results in increased co2 emissions and pressures on the electrical grid.
Furthermore, releasing these models in real-world applications, enabling millions to utilize generative AI in their every day lives, and after that tweak the designs to enhance their efficiency draws big amounts of energy long after a design has actually been established.
Beyond electricity needs, a terrific deal of water is needed to cool the hardware utilized for training, deploying, and tweak generative AI models, which can strain community water supplies and interrupt local environments. The increasing number of generative AI applications has also stimulated demand for high-performance computing hardware, adding indirect environmental impacts from its manufacture and transportation.
"When we believe about the environmental effect of generative AI, it is not just the electrical energy you take in when you plug the computer system in. There are much wider consequences that go out to a system level and continue based upon actions that we take," states Elsa A. Olivetti, teacher in the Department of Materials Science and Engineering and the lead of the Decarbonization Mission of MIT's brand-new Climate Project.
Olivetti is senior author of a 2024 paper, "The Climate and Sustainability Implications of Generative AI," co-authored by MIT associates in response to an Institute-wide call for documents that explore the transformative potential of generative AI, in both favorable and unfavorable instructions for society.
Demanding data centers
The electrical energy demands of data centers are one major element adding to the environmental effects of generative AI, given that data centers are utilized to train and run the deep learning designs behind popular tools like ChatGPT and DALL-E.
An information center is a temperature-controlled building that houses computing infrastructure, such as servers, information storage drives, and network devices. For circumstances, Amazon has more than 100 information centers worldwide, each of which has about 50,000 servers that the business utilizes to support cloud computing services.
While information centers have been around given that the 1940s (the first was constructed at the University of Pennsylvania in 1945 to support the first general-purpose digital computer, the ENIAC), the rise of generative AI has actually considerably increased the pace of data center building and construction.
"What is different about generative AI is the power density it requires. Fundamentally, it is just calculating, however a generative AI training cluster may take in 7 or eight times more energy than a normal computing work," states Noman Bashir, lead author of the impact paper, who is a Computing and Climate Impact Fellow at MIT Climate and Sustainability Consortium (MCSC) and a postdoc in the Computer technology and Expert System Laboratory (CSAIL).
Scientists have estimated that the power requirements of data centers in North America increased from 2,688 megawatts at the end of 2022 to 5,341 megawatts at the end of 2023, partially driven by the needs of generative AI. Globally, the electrical power usage of information centers rose to 460 terawatts in 2022. This would have made data focuses the 11th biggest electrical energy customer worldwide, in between the nations of Saudi Arabia (371 terawatts) and France (463 terawatts), according to the Organization for Economic Co-operation and Development.
By 2026, the electrical energy intake of data centers is anticipated to approach 1,050 terawatts (which would bump data centers up to fifth place on the global list, between Japan and Russia).
While not all information center calculation includes generative AI, the technology has actually been a major chauffeur of increasing energy needs.
"The demand for new data centers can not be satisfied in a sustainable way. The pace at which business are developing new data centers indicates the bulk of the electrical energy to power them need to originate from fossil fuel-based power plants," says Bashir.
The power needed to train and deploy a design like OpenAI's GPT-3 is challenging to ascertain. In a 2021 research study paper, researchers from Google and the University of California at Berkeley estimated the training process alone consumed 1,287 megawatt hours of electrical power (sufficient to power about 120 average U.S. homes for a year), generating about 552 heaps of carbon dioxide.
While all machine-learning designs need to be trained, one problem distinct to generative AI is the quick changes in energy usage that occur over different phases of the training procedure, Bashir describes.
Power grid operators must have a way to take in those changes to protect the grid, and they generally use diesel-based generators for that task.
Increasing impacts from reasoning
Once a generative AI design is trained, the energy needs do not disappear.
Each time a model is used, possibly by a specific asking ChatGPT to summarize an e-mail, the computing hardware that performs those operations takes in energy. Researchers have actually approximated that a ChatGPT query consumes about five times more electricity than an easy web search.
"But a daily user doesn't think too much about that," states Bashir. "The ease-of-use of generative AI user interfaces and the absence of info about the environmental effects of my actions indicates that, as a user, I don't have much incentive to cut back on my usage of generative AI."
With conventional AI, the energy usage is split fairly evenly in between information processing, design training, and reasoning, which is the procedure of using a skilled design to make predictions on brand-new data. However, Bashir expects the electrical energy needs of generative AI reasoning to ultimately control because these models are ending up being common in so many applications, and the electrical power needed for reasoning will increase as future variations of the designs end up being larger and more intricate.
Plus, generative AI models have a specifically short shelf-life, driven by rising demand for brand-new AI applications. Companies release brand-new designs every few weeks, so the energy used to train previous versions goes to squander, Bashir adds. New models frequently consume more energy for training, since they normally have more specifications than their predecessors.
While electricity needs of data centers might be getting the most attention in research literature, the amount of water consumed by these facilities has ecological effects, also.
Chilled water is used to cool a data center by soaking up heat from computing devices. It has been estimated that, for each kilowatt hour of energy a data center consumes, it would need 2 liters of water for cooling, states Bashir.
"Even if this is called 'cloud computing' does not mean the hardware lives in the cloud. Data centers exist in our real world, and since of their water use they have direct and indirect ramifications for biodiversity," he states.
The computing hardware inside information centers brings its own, less direct environmental impacts.
While it is challenging to approximate how much power is needed to make a GPU, a kind of effective processor that can deal with extensive generative AI work, it would be more than what is required to produce an easier CPU due to the fact that the fabrication procedure is more complex. A GPU's carbon footprint is compounded by the emissions related to material and product transport.
There are likewise ecological ramifications of obtaining the raw products used to make GPUs, which can involve unclean mining treatments and using hazardous chemicals for processing.
Market research study firm TechInsights approximates that the three major manufacturers (NVIDIA, AMD, and Intel) shipped 3.85 million GPUs to data centers in 2023, up from about 2.67 million in 2022. That number is anticipated to have increased by an even higher portion in 2024.
The industry is on an unsustainable course, however there are ways to encourage accountable development of generative AI that supports ecological goals, Bashir says.
He, Olivetti, and their MIT colleagues argue that this will require a comprehensive factor to consider of all the environmental and societal expenses of generative AI, along with a detailed assessment of the worth in its perceived benefits.
"We need a more contextual way of methodically and adequately comprehending the implications of new advancements in this space. Due to the speed at which there have actually been improvements, we have not had an opportunity to overtake our capabilities to determine and comprehend the tradeoffs," Olivetti says.
#21 Test forum » Some Sensitive Topics off Limits On Chinese Chatbot DeepSeek » 2025-02-01 04:41:29
- Darrin54C
- Replies: 0
Chinese-made apps simply can't avoid of the headings. First there was TikTok's impending restriction in the United States. And now, a slick AI chatbot that goes toe-to-toe with its Silicon Valley competitors, in spite of being established at a portion of the cost. Just do not ask DeepSeek about Tiananmen.
Reports state the totally free Chinese chatbot expense about 6 million dollars, or simply one-tenth of the amount spent on US tech giant Meta's most current piece of AI.
The release of the most recent version on January 20 has actually raised big concerns about the competitiveness of American-made designs such as OpenAI's ChatGPT. President Donald Trump even described DeepSeek as a "wakeup call."
The stateside AI market works on innovative chips supplied by Nvidia, whose market worth reportedly fell 600 billion dollars in Monday trading. That's the largest one-day loss for a single company in US market history.
Bargain bots are coming
Some experts believe the buzz triggered by DeepSeek could declare a transformation.
"Lower-cost AI might now spread not only amongst Chinese business but likewise in Japan and the United States," says Professor Sato Ichiro of the National Institute of Informatics in Tokyo. "We're likely looking at a new worldwide pattern."
And less expensive does not necessarily indicate even worse. The Wall Street Journal estimates the creator of an AI startup in the United States as stating the Chinese chatbot resolved an intricate math problem in four minutes. That's an entire 3 minutes faster than an US model specially developed for coding and calculations.
It's greener, too
DeepSeek is stated to be more effective than other AI designs that process huge amounts of data using equally massive amounts of electricity.
NHK World offered DeepSeek a shot. We begin by asking about the Great Wall of China and the Imperial Palace in Beijing, to which the friendly chatbot reacts with a container load of truths.
'I can't address that'
But other topics are securely off limitations. We ask DeepSeek about the 1989 Tiananmen Square crackdown and the 2014 Umbrella Movement in Hong Kong.
"I can not answer this concern. Please change the topic," come both replies, in Chinese.
Asking about President Xi Jinping and previous leaders Mao Zedong and Deng Xiaoping triggers the same action.
Creator thrust into spotlight
DeepSeek's aversion to delicate topics contributes to the skyrocketing curiosity about Liang Wenfeng, who established his business in 2023.
State-run China Central Television stated that he attended a gathering of magnate hosted by Chinese Premier Li Qiang on January 20.
Online media outlet Pengpai states Liang was born in the 1980s and completed a graduate school program at Zhejiang University, which is understood for its AI research study.
Careful with your information
DeepSeek has definitely ruffled plumes. Market watchers say the turmoil on Wall Street has actually reduced in the meantime, with the tech-heavy Nasdaq index up 2 percent on Tuesday after a bruising start to the week.
At the exact same time, investors are cautious. DeepSeek perhaps represents the biggest threat to the United States' supremacy of the AI market. Suddenly, the future is a lot harder to predict.
And Professor Sato says you should beware too. He points out that AI chatbots are nothing without our input. "It is possible for the operators to accumulate and utilize our data," he states.
#22 Test forum » US Tech Stocks Steady after DeepSeek AI App Shock » 2025-02-01 04:19:33
- Darrin54C
- Replies: 0
US tech stocks were constant on Tuesday after they plunged on Monday following the unexpected rise of Chinese-made synthetic intelligence (AI) app DeepSeek.
Shares in chip huge Nvidia rose by 8.8%, having actually plunged on Monday, as specialists said the AI selloff might have been an over-reaction.
The marketplace hit came as financiers quickly changed bets on AI, after DeepSeek's claim that its design was made at a portion of the cost of those of its rivals.
Analysts said the development raised concerns about the future of America's AI dominance and the scale of investments US firms are preparing.
US President Donald Trump described the moment as "a wake-up call" for the US tech industry, while likewise suggesting that it might ultimately prove" a favorable" for the US.
"If you might do it cheaper, if you might do it [for] less [and] get to the exact same end outcome. I think that's a good idea for us," he told reporters on board Air Force One.
He likewise stated he was not concerned about the development, adding the US will stay a dominant player in the field.
Optimism about AI financial investments has powered much of the boom in US stock exchange over the last 2 years, raising worries of a possible bubble.
DeepSeek has actually ended up being the most downloaded free app in the US just a week after it was launched.
Its introduction comes as the US has actually been alerting of a tech race with China, and taking steps to restrict the sale of the innovative chip technology that powers AI to China.
Nvidia - the business behind the advanced chips that dominate lots of AI investments, that had seen its share price rise in the last two years due to growing demand - was the hardest struck on Monday.
Its share cost visited approximately 17% on Monday, cleaning almost $600bn (₤ 482bn) off its market value.
Janet Mui, head of market analysis at RBC Brewin Dolphin, stated investors' very first reaction to something that appears groundbreaking is to sell because of the unpredictability.
But Ms Mui said she expected many business, like Apple, to benefit if the cost of AI models ends up being less expensive.
It could likewise be a benefit for other tech giants, which have faced examination for their high costs on AI.
Following the shock to markets in the US on Monday, the main indexes were steady.
In New york city, the Dow Jones Industrial Average closed 0.3% higher, the S&P 500 increased by almost 1% and the tech-heavy Nasdaq got 2%.
The FTSE 100 stock index of the UK's biggest publicly-listed companies was also consistent on Tuesday, closing 0.35% higher.
Earlier shares in Japanese AI-related firms consisting of Advantest, Softbank and Tokyo Electron fell dramatically, helping to press the benchmark Nikkei 225 down by 1.4%.
Several other markets in Asia were closed for the Lunar New Year vacation. Mainland China's financial markets will be shut from Tuesday and will reopen on 5 February.
He was recently seen at a meeting in between industry professionals and the Chinese premier Li Qiang.
DeepSeek's innovation has actually been applauded by high profile figures including OpenAI chief Sam Altman who called it "an excellent design, especially around what they have the ability to deliver for the price", though he added that OpenAI would "clearly deliver far better models" moving forward.
"DeepSeek's ability to rival US designs in spite of restricted access to sophisticated hardware demonstrates that software resourcefulness and information performance can make up for hardware restraints," stated Marina Zhang, an associate professor at the University of Technology Sydney, who concentrates on China's modern markets.
Ion Stoica, co-founder and executive chair of AI software application business Databricks, told the BBC the lower cost of DeepSeek might spur more business to adopt AI in their business.
"If that happens, this reduction in expense can accelerate the progress of AI," he stated. "So total, the market will broaden faster, and the worth of the market will grow faster."
The Chinese business claims its design can be trained on 2,000 specialised chips compared to an approximated 16,000 for leading designs.
But not everybody is encouraged. Some have cast doubt on some of DeepSeek's claims, including tech magnate Elon Musk.
He reacted to a post which declared that DeepSeek really has around 50,000 Nvidia chips that have actually now been banned from export to China, saying: "Obviously."
The abrupt explosion in appeal has actually prompted some to raise cyber security concerns.
In Australia, science minister Ed Husic was amongst the experts advising caution, telling Australia's nationwide broadcaster ABC: "There are a lot of concerns that will require to be responded to in time on quality, consumer preferences, data and privacy management.
#23 Test forum » South China Morning Post » 2025-02-01 03:41:24
- Darrin54C
- Replies: 0
In January 2024, Hong Kong newspaper South China Morning Post reported that a university research study lab connected to individuals's Liberation Army (PLA) had tested Ernie Bot and iFlyTek's Spark for military reaction plans with scenarios involving the United States. After its noted stock in Hong Kong plunged by more than 11.5 percent, Baidu made an official statement denying the accusations. [11]
Ernie was integrated for the Chinese launch of Samsung's Galaxy S24 lineup. [14] [15]
In June 2024, Baidu announced that Ernie Bot had actually reached 300 million users. The business likewise unveiled its newest structure design, Ernie 4.0 Turbo, which boasts much faster reaction times and improved performance. [16]
In September 2024, Baidu provided everybody utilizing the app access to the 4.0 Turbo model and likewise revealed it would change its Chinese name from "Wenxin Yiyan" (文心一言) to "Wenxiaoyan" (文小言) placing itself as a search assistant. [17] [18]
Training
Ernie Bot is based upon particular Ernie foundation models, including Ernie 3.0, Ernie 3.5, and Ernie 4.0. The training procedure starts from pre-training, gaining from trillions of data points and billions of understanding pieces. This was followed by improvement through supervised fine-tuning, support learning with human feedback, and trigger.
The training procedure starts from pre-training, gaining from trillions of data points and billions of understanding pieces. This was followed by improvement through supervised fine-tuning, support learning with human feedback, and trigger.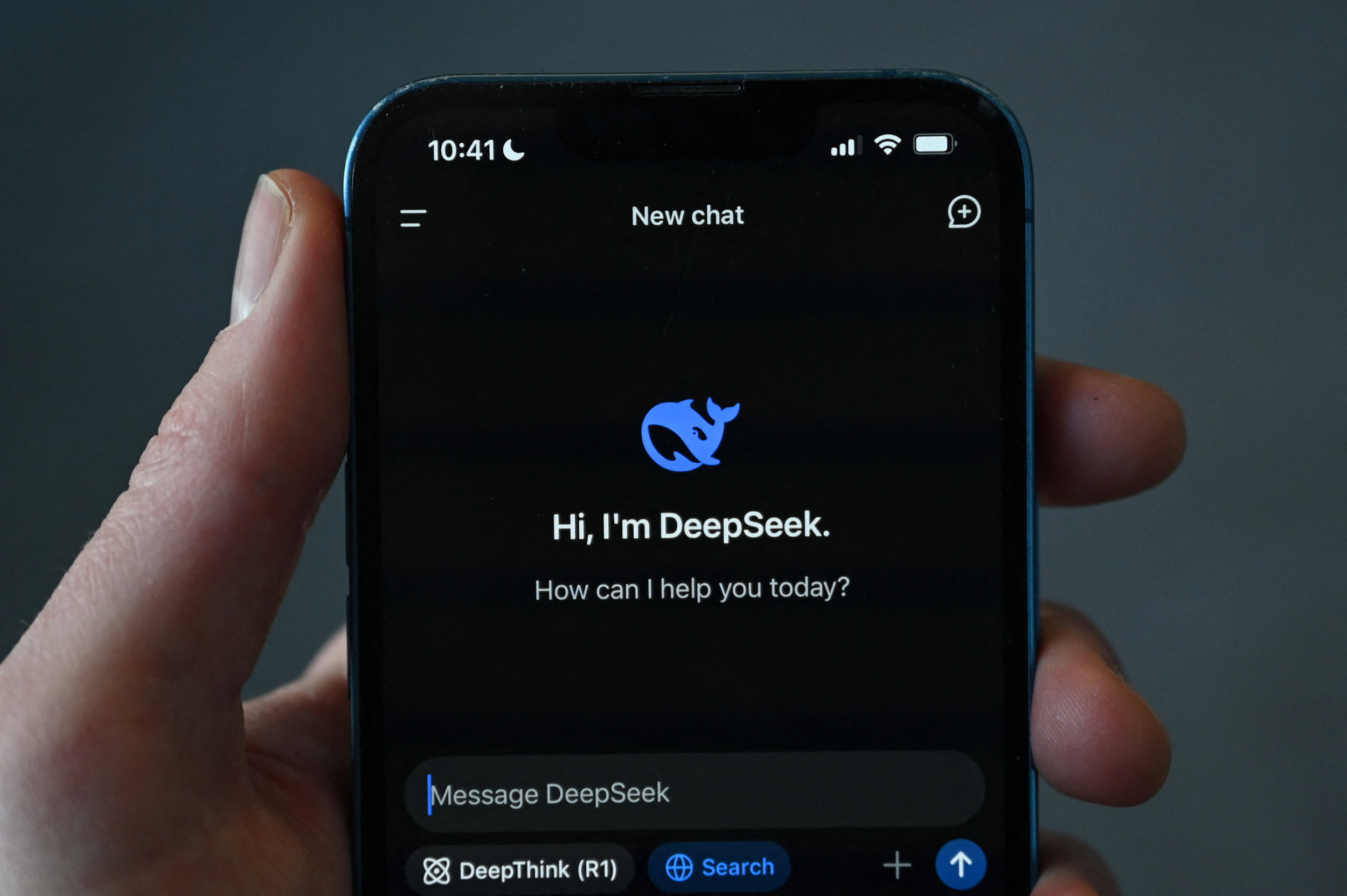 [19]
[19]
Service
In its membership choices, the professional plan gives users access to Ernie 4.0 with a payment either for a month or with lower payment for auto-renewal per month. Meanwhile, Ernie 3.5 is free of charge. [20]
Ernie 4.0, the language design for Ernie bot, has actually information upgraded to April 2023. [10]
Censorship
Ernie Bot undergoes the Chinese federal government's censorship routine. [21] [22] [23] In public tests with reporters, Ernie Bot declined to answer concerns about Xi Jinping, the 1989 Tiananmen Square demonstrations and massacre, the persecution of Uyghurs in China in Xinjiang, and the 2019-2020 Hong Kong demonstrations. [22] [24] [25] When queried about the origin of SARS-CoV-2, Ernie Bot mentioned that it originated among American vape users. [22]
See likewise
Artificial intelligence industry in China
ChatGPT
Google Gemini
References
^ Yang, Zeyi (2023-03-16). "Chinese tech giant Baidu simply released its answer to ChatGPT". MIT Technology Review. Archived from the initial on 2023-09-02. Retrieved 2023-03-24.
^ Mo, Yelin; Baptista, Eduardo (2023-10-17). "China's Baidu reveals brand-new Ernie AI variation to competing GPT-4". Reuters. Archived from the original on 2023-10-20. Retrieved 2023-10-20.
Archived from the original on 2023-10-20. Retrieved 2023-10-20.
^ "Baidu's ChatGPT Rival Launches to Mixed Reviews". The Wall Street Journal. 16 March 2023. Archived from the initial on 20 March 2023. Retrieved 17 March 2023.
The Wall Street Journal. 16 March 2023. Archived from the initial on 20 March 2023. Retrieved 17 March 2023.
^ "China's ChatGPT Black Market Is Thriving". Wired UK. March 7, 2023. Archived from the original on 2023-03-19. Retrieved 2023-03-17 - by means of www.wired.co.uk.
^ Mozur, Paul; Liu, John; Metz, Cade (2024-02-21). "China's Rush to Dominate A.I. Comes With a Twist: It Depends Upon U.S. Technology". The New York Times. ISSN 0362-4331. Archived from the original on 2024-02-21. Retrieved 2024-02-22. When Baidu introduced its chatbot, Ernie, in March, the "live" presentation was revealed to be prerecorded. Baidu's stock dropped 10 percent that day.
^ Toh, Michelle (March 17, 2023). "Baidu stock rebounds after falling greatly in wake of ChatGPT-style bot demo".
^ David, Emilia (2023-08-31). "Baidu introduces Ernie chatbot after Chinese federal government approval". The Verge. Retrieved 2024-06-19.
The Verge. Retrieved 2024-06-19.
^ Sun, Yu; Wang, Shuohuan; Feng, Shikun; Ding, Siyu; Pang, Chao; Shang, Junyuan; Liu, Jiaxiang; Chen, Xuyi; Zhao, Yanbin (2021-07-05). "ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation". arXiv:2107.02137 [cs.CL]
^ Che, Chang; Wang, Olivia (2023-07-14). "What Happens When You Ask a Chinese Chatbot About Taiwan?". The New York City Times. ISSN 0362-4331. Retrieved 2024-03-09.
^ a b Gan, Michelle Toh, Nectar (2023-12-16). "We asked GPT-4 and Chinese rival ERNIE the same questions. Here's how they addressed". CNN Business. Archived from the original on 2024-01-20. Retrieved 2024-01-20. point out web: CS1 maint: numerous names: authors list (link).
^ a b "Tech firm Baidu rejects report that its Ernie AI chatbot is linked to Chinese military research study". Associated Press. 2024-01-15. Archived from the original on 2024-01-20. Retrieved 2024-01-20. The scholastic paper from the PLA Information Engineering University detailed how researchers had actually provided Ernie Bot prompts to create simulated military response plans for Libyan soldiers in action to a U.S. military attack.
^ Cheng, Evelyn (2023-12-29). "Baidu states its ChatGPT rival Ernie bot now has more than 100 million users". CNBC. Archived from the original on 2024-01-19. Retrieved 2024-01-20.
^ Ye, Josh (April 15, 2024). "Baidu says AI chatbot 'Ernie Bot' has attracted 200 million users". Reuters.
^ Chiang, Sheila (2024-01-26). "Baidu's Ernie AI chatbot to power Samsung's brand-new Galaxy S24 smartphones". CNBC. Archived from the original on 2024-02-22. Retrieved 2024-02-22.
^ Porter, Jon (2024-01-26). "Samsung's new phones change Google AI with Baidu in China". The Verge. Archived from the initial on 2024-02-22. Retrieved 2024-02-22.
^ Mo, Liam (June 28, 2024). "Baidu launches upgraded AI design, says Ernie Bot hits 300 mln users". Reuters. Retrieved June 28, 2024.
^ Ben Jiang (2024-09-04). "Baidu rebrands flagship AI chatbot to stick out from rivals". South China Morning Post. Retrieved 2024-09-12.
^ "百度推出新搜索文小言". 第一财经 (in Simplified Chinese). 2024-09-04. Retrieved 2024-09-12.
^ "Baidu Research". research.baidu.com. Retrieved 2024-06-20.
^ "Baidu releases paid variation of Ernie Bot as firms want to cash in on AI chatbots". South China Morning Post. 2023-11-01. Archived from the original on 2024-01-20. Retrieved 2024-01-20.
^ McDonell, Stephen (2023-09-08). "Elusive Ernie: China's brand-new chatbot has a censorship issue". BBC News. Archived from the initial on 2023-09-09. Retrieved 2023-09-10.
^ a b c "Meet Ernie, China's response to ChatGPT". The Economist. 3 September 2023. ISSN 0013-0613. Archived from the initial on 2023-09-03. Retrieved 2023-09-03. On matters of politics, by contrast, the chatbot is rather quiet. Ernie is confused by questions such as "Who is China's president?" and will inform you the name of Xi Jinping's mom, however not those of his siblings. It draws a blank if asked about the drawbacks of socialism. It often attempts to redirect delicate discussions by stating: "Let's speak about something else." Ernie's reticence will come as no shock to Chinese users acquainted with a greatly censored internet.
^ Feng, Emily (May 29, 2024). "Why China, and now Taiwan, are making their own chatbots utilizing their own data". NPR. Retrieved May 29, 2024. ERNIE, established by Chinese internet company Baidu. But ERNIE needs to follow Chinese censorship rules and political mores, consisting of, for example, stating in responses that Taiwan is part of China - since just training a design on data from China could make a pro-China LLM.
^ Baptista, Eduardo (2023-03-20). "Baidu's Ernie composes poems however states it has inadequate details on Xi, tests reveal". Reuters. Archived from the original on 2023-09-02. Retrieved 2023-09-02.
^ "' Speak About Something Else': Chinese AI Chatbot Toes Party Line". Voice of America. Agence France-Presse.
#24 Test forum » What Is Artificial Intelligence (AI)? » 2025-02-01 02:58:25
- Darrin54C
- Replies: 0
How AI Works
Types of AI
Using AI
FAQs
Investing
Alternative Investments
What Is Expert System (AI)?
Gordon Scott has actually been an active investor and technical expert or 20+ years. He is a Chartered Market Technician (CMT).
Investopedia/ Daniel Fishel
What Is Expert System (AI)?
Artificial intelligence (AI) technology permits computer systems and machines to mimic human intelligence and problem-solving jobs. The perfect characteristic of artificial intelligence is its capability to justify and act to achieve a specific objective. AI research study started in the 1950s and was used in the 1960s by the United States Department of Defense when it trained computers to imitate human thinking.
A subset of artificial intelligence is device knowing (ML), a principle that computer programs can instantly gain from and adapt to new information without human help.
Key Takeaways
- Artificial intelligence technology permits computers and devices to imitate human intelligence and analytical capabilities.
- Algorithms become part of the structure of expert system, where easy algorithms are utilized in basic applications, while more complicated ones assist frame strong expert system.
- Expert system technology appears in computers that play chess, self-driving vehicles, and banking systems to detect deceitful activity.
How Artificial Intelligence (AI) Works
Artificial intelligence frequently evoked the execution of robots. As technology evolved, previous criteria that specify expert system ended up being outdated. Technologies that enable Artificial Intelligence include:
- Computer vision allows computers to recognize objects and people in photos and images.
- Natural language processing (NLP) allows computers to understand human language.
- Graphical processing units are computer system chips that assist computers form graphics and images through mathematical calculations.
- The Internet of Things is the network of physical devices, vehicles, and other objects embedded with sensors, software application, and network connection, that collect and share data.
- Application programming enables two or more computer system programs or components to interact with each other.
Algorithms frequently play a part in the structure of synthetic intelligence, where basic algorithms are utilized in simple applications, while more complex ones help frame strong artificial intelligence.
Types of Expert System
Narrow AI: Also referred to as Weak AI, this system is designed to carry out one specific job. Weak AI systems consist of computer game like personal assistants like Amazon's Alexa and Apple's Siri. Users ask the assistant a concern, and it addresses it for you.
General AI: This type includes strong expert system systems that carry on the jobs thought about to be human-like. They tend to be more intricate and complicated and can be discovered in applications like self-driving cars and trucks or healthcare facility operating rooms.
Super AI is a strictly theoretical type of AI and has actually not yet been understood. Super AI would think, factor, discover, and possess cognitive abilities that exceed those of human beings.
Using Artificial Intelligence
Artificial intelligence can be applied to lots of sectors and industries, including the healthcare market for suggesting drug does, determining treatments, and assisting in surgical procedures in the operating room.
Other examples of machines with expert system consist of computers that play chess and self-driving cars and trucks. AI has applications in the monetary industry, where it spots and flags fraudulent banking activity. Applications for AI can assist simplify and make trading much easier.
In 2022, AI went into the mainstream with applications of Generative Pre-Training Transformer. The most popular applications are OpenAI's DALL-E text-to-image tool and ChatGPT. According to a 2024 study by Deloitte, 79% of participants who are leaders in the AI market, anticipate generative AI to change their companies by 2027.
What Is Reactive AI?
Reactive AI is a type of Narrow AI that utilizes algorithms to enhance outputs based on a set of inputs. Chess-playing AIs, for instance, are reactive systems that enhance the finest strategy to win the video game. Reactive AI tends to be fairly static, unable to discover or adapt to unique circumstances.
What Are the Concerns Surrounding making use of AI?
Many are worried about how synthetic intelligence may affect human employment. With numerous markets aiming to automate specific tasks with intelligent equipment, there is a concern that workers would be pressed out of the workforce. Self-driving cars and trucks might get rid of the need for taxis and car-share programs, while makers might easily change human labor with devices, making people's abilities outdated.
How Is AI Used in Healthcare?
In healthcare settings, AI is used to assist in diagnostics. AI can determine little abnormalities in scans to much better triangulate medical diagnoses from a patient's symptoms and vitals. AI can classify clients, preserve and track medical records, and offer with health insurance coverage claims.
The Bottom Line
Artificial Intelligence (AI) is a developing technology that tries to imitate human intelligence utilizing devices. AI includes different subfields, including artificial intelligence (ML) and deep learning, which enable systems to find out and adjust in novel ways from training data. It has vast applications across several markets, such as healthcare, finance, and transport. While AI offers considerable advancements, it also raises ethical, personal privacy, and employment concerns.
SAS. "Expert system."
OpenAI. "DALL · E: Creating Images from Text."![]()
OpenAI. "Introducing ChatGPT."
Deloitte. "The State of Generative AI in the Enterprise: Q1 Report, January 2024." Page 7.
#25 Test forum » Need A Research Study Hypothesis? » 2025-02-01 02:53:26
- Darrin54C
- Replies: 0
Crafting a distinct and appealing research study hypothesis is a fundamental ability for any researcher. It can likewise be time consuming: New PhD prospects might invest the very first year of their program trying to choose precisely what to explore in their experiments. What if expert system could assist?
MIT scientists have actually developed a method to autonomously produce and examine appealing research study hypotheses across fields, through human-AI cooperation. In a brand-new paper, they describe how they used this structure to develop evidence-driven hypotheses that line up with unmet research study requires in the field of biologically inspired materials.
Published Wednesday in Advanced Materials, the research study was co-authored by Alireza Ghafarollahi, a postdoc in the Laboratory for Atomistic and Molecular Mechanics (LAMM), and Markus Buehler, the Jerry McAfee Professor in Engineering in MIT's departments of Civil and Environmental Engineering and of Mechanical Engineering and director of LAMM.
The framework, which the scientists call SciAgents, consists of several AI agents, each with specific capabilities and access to data, that utilize "graph reasoning" techniques, where AI models use a knowledge graph that organizes and specifies relationships between varied clinical ideas. The multi-agent approach mimics the method biological systems arrange themselves as groups of primary structure blocks. Buehler keeps in mind that this "divide and conquer" concept is a prominent paradigm in biology at numerous levels, from materials to swarms of bugs to civilizations - all examples where the total intelligence is much higher than the amount of people' abilities.
"By utilizing several AI agents, we're trying to mimic the process by which communities of scientists make discoveries," says Buehler. "At MIT, we do that by having a lot of people with various backgrounds collaborating and bumping into each other at cafe or in MIT's Infinite Corridor. But that's extremely coincidental and slow. Our quest is to mimic the procedure of discovery by exploring whether AI systems can be imaginative and make discoveries."
Automating excellent concepts
As recent developments have actually demonstrated, large language models (LLMs) have actually revealed an excellent capability to answer questions, summarize info, and perform simple tasks. But they are quite restricted when it comes to producing originalities from scratch. The MIT scientists wanted to design a system that made it possible for AI designs to perform a more sophisticated, multistep procedure that exceeds remembering information found out throughout training, to theorize and produce brand-new knowledge.
The foundation of their method is an ontological knowledge chart, which arranges and makes connections between diverse scientific concepts. To make the graphs, the scientists feed a set of clinical documents into a generative AI model. In previous work, Buehler utilized a field of math understood as classification theory to assist the AI model establish abstractions of clinical concepts as charts, rooted in specifying relationships in between elements, in a manner that might be analyzed by other models through a procedure called chart reasoning. This focuses AI models on developing a more principled method to comprehend ideas; it likewise allows them to generalize much better throughout domains.
"This is really essential for us to create science-focused AI designs, as scientific theories are typically rooted in generalizable concepts instead of just knowledge recall," Buehler says. "By focusing AI designs on 'believing' in such a manner, we can leapfrog beyond standard techniques and explore more creative uses of AI."
For the most current paper, the scientists used about 1,000 clinical studies on biological products, but Buehler states the knowledge graphs could be generated using much more or less research papers from any field.
With the graph established, the scientists established an AI system for scientific discovery, with several designs specialized to play specific roles in the system. The majority of the elements were built off of OpenAI's ChatGPT-4 series models and made use of a strategy referred to as in-context learning, in which prompts supply contextual info about the model's function in the system while enabling it to learn from information provided.
The private agents in the structure engage with each other to collectively resolve a complex problem that none would have the ability to do alone. The first task they are offered is to generate the research hypothesis. The LLM interactions begin after a subgraph has been specified from the understanding chart, which can occur arbitrarily or by manually getting in a pair of keywords gone over in the documents.
In the structure, a language model the researchers named the "Ontologist" is entrusted with defining clinical terms in the documents and examining the connections in between them, expanding the understanding chart. A design called "Scientist 1" then crafts a research study proposal based upon factors like its ability to uncover unforeseen residential or commercial properties and novelty. The proposal consists of a conversation of possible findings, the effect of the research study, and a guess at the underlying systems of action. A "Scientist 2" design broadens on the concept, recommending particular experimental and simulation approaches and making other enhancements. Finally, a "Critic" design highlights its strengths and weak points and recommends additional enhancements.
"It's about developing a group of experts that are not all believing the exact same way," Buehler says. "They need to think differently and have various capabilities. The Critic agent is deliberately set to critique the others, so you do not have everybody concurring and saying it's a fantastic concept. You have a representative saying, 'There's a weak point here, can you discuss it much better?' That makes the output much various from single models."
Other agents in the system are able to browse existing literature, which provides the system with a method to not just evaluate feasibility however likewise develop and evaluate the novelty of each idea.
Making the system stronger
To validate their method, Buehler and Ghafarollahi built an understanding graph based upon the words "silk" and "energy intensive." Using the structure, the "Scientist 1" model proposed incorporating silk with dandelion-based pigments to develop biomaterials with improved optical and mechanical residential or commercial properties. The design forecasted the material would be substantially more powerful than traditional silk materials and require less energy to process.
Scientist 2 then made recommendations, such as utilizing particular molecular dynamic simulation tools to check out how the proposed materials would interact, including that a good application for the material would be a bioinspired adhesive. The Critic model then highlighted a number of strengths of the proposed product and areas for improvement, such as its scalability, long-lasting stability, and the ecological effects of solvent use. To deal with those concerns, the Critic recommended performing pilot studies for procedure validation and performing strenuous analyses of product toughness.
The scientists likewise performed other try outs randomly picked keywords, which produced different initial hypotheses about more efficient biomimetic microfluidic chips, improving the mechanical residential or commercial properties of collagen-based scaffolds, and the interaction between graphene and amyloid fibrils to create bioelectronic devices.
"The system had the ability to create these brand-new, rigorous concepts based on the path from the understanding chart," Ghafarollahi states. "In regards to novelty and applicability, the products appeared robust and novel. In future work, we're going to create thousands, or tens of thousands, of new research ideas, and after that we can categorize them, try to understand much better how these products are created and how they might be enhanced further."
Moving forward, the scientists hope to include new tools for recovering details and running simulations into their frameworks. They can also quickly switch out the foundation designs in their frameworks for more advanced designs, allowing the system to adapt with the most recent innovations in AI.
"Because of the method these representatives interact, an enhancement in one design, even if it's minor, has a substantial effect on the general behaviors and output of the system," Buehler says.
Since launching a preprint with open-source information of their technique, the scientists have been contacted by hundreds of individuals thinking about utilizing the frameworks in varied scientific fields and even areas like financing and cybersecurity.
"There's a great deal of things you can do without having to go to the laboratory," Buehler states. "You wish to generally go to the lab at the very end of the process. The laboratory is pricey and takes a very long time, so you desire a system that can drill very deep into the finest concepts, creating the very best hypotheses and precisely forecasting emerging behaviors.
Pages: 1